

서 론
연구방법
환경변수 설정
다중공선성 분석
Geo-Similarity 기반 비화재 샘플링
TPOT 기반 모델 탐색 및 최적화
모델 평가 기준
연구결과
다중공선성 분석 결과
TPOT 기반 산불 취약성 평가
모델 성능 및 SCAI 분석 결과
토 론
Geo-Similarity 샘플링의 효과
AutoML (TPOT) 기반 모델의 성능 해석
SCAI를 통한 공간적 일치도 평가
한계점 및 향후 연구 방향
결 론
서 론
최근 기후변화로 인한 이상고온과 장기 가뭄의 빈도가 증가함에 따라 전 세계적으로 산불 발생 위험이 급격히 확대되고 있다. 우리나라 또한 2025년 경북 지역에서 발생한 초대형 산불을 비롯하여 대형 산불의 빈도가 증가하고 있으며, 산불로 인한 인명 피해와 경제적 손실이 국가적 차원의 주요 방재 과제로 대두되고 있다(Sim et al., 2020; Lee et al., 2024). 이에 따라 산불의 공간적 발생 가능성을 정량적으로 예측하고, 취약 지역을 사전에 파악하기 위한 산불 취약성 지도(wildfire susceptibility map) 작성의 중요성이 점차 강조되고 있다(Jeong and Son, 2025).
기존의 산불 취약성 평가는 주로 통계적 회귀분석(logistic regression) 또는 결정트리(decision tree) 기반의 전통적 기계학습 모델을 활용하여 수행되어 왔다. 그러나 이러한 접근법은 입력 변수의 조합과 하이퍼파라미터 설정이 전문가의 경험에 의존하며, 데이터 불균형(data imbalance)과 지역별 이질성(spatial heterogeneity)을 충분히 반영하지 못하는 한계가 있다. 특히 비화재 지역(non-fire sample)의 샘플링 방법에 따라 모델의 공간 예측 성능이 크게 달라지므로, 학습 데이터의 대표성을 확보하는 것이 산불 예측 정확도 향상의 핵심 요소로 지적되고 있다. 이러한 한계를 보완하기 위해 최근에는 공간정보와 인공지능을 융합한 GeoAI (geospatial artificial intelligence) 기술이 주목받고 있다(Nam et al., 2024). GeoAI는 위성영상, 지형인자, 토지피복, 인공지형 요소 등 다양한 공간 데이터를 통합하여 기계학습 또는 심층학습 모델을 자동화된 방식으로 최적화할 수 있는 장점을 갖는다. 특히 AutoML (automated machine learning)은 알고리즘 선택과 하이퍼파라미터 탐색을 자동으로 수행함으로써, 수작업 기반 모델링의 시간과 불확실성을 크게 줄일 수 있다. 그중 TPOT (Tree-based Pipeline Optimization Tool)은 진화 알고리즘을 기반으로 한 AutoML 프레임워크로, 다양한 모델 조합을 탐색하여 최적의 머신러닝 파이프라인을 자동으로 구축할 수 있다(Nam et al., 2025).
본 연구에서는 이러한 GeoAI 개념을 기반으로, AutoML과 Geo-Similarity 기반 샘플링을 결합하여 산불 취약성 예측 모델을 구축하였다. Geo-Similarity Sampling은 화재 발생 지점과 유사한 지리적·환경적 특성을 가지면서 실제로 화재가 발생하지 않은 지점을 비화재 샘플로 선정하는 기법으로, 데이터 불균형 문제를 완화하고 모델의 일반화 성능을 향상시키는 데 효과적이다. 또한 단순한 정확도(accuracy, ACC)나 AUC (area under the curve) 기반의 성능 평가를 넘어, 예측 결과의 공간적 일치도를 정량화하기 위해 공간분류정확도지수(spatial classification accuracy index, SCAI)를 도입하였다. SCAI는 각 취약성 등급별 면적 비율과 실제 화재 발생 비율 간의 상대적 차이를 비교함으로써, 모델의 공간 분류 신뢰성을 평가하는 지표이다(Rabby et al., 2023). 따라서 본 연구의 목적은 (1) AutoML 기반 산불 취약성 예측 모델의 성능을 비교·분석하고, (2) Geo-Similarity 기반 샘플링이 공간적 분류 정확도에 미치는 영향을 검증하며, (3) SCAI를 활용하여 각 모델의 공간적 일치성을 평가하는 데 있다. 이를 통해 산불 취약성 지도 작성의 정량적 신뢰성을 향상시키고, 향후 인공지능 기반 산불 방재 의사결정 시스템 구축에 기여하고자 한다.
연구방법
환경변수 설정
산불의 발생 및 확산에 영향을 미치는 환경요인을 정량적으로 분석하기 위해 지형적, 산림, 인위적 환경, 기후적 요인 등 총 12개의 공간변수를 구축하였다(Fig. 1). 모든 변수는 공간 해상도 30 m, 좌표계 EPSG:32652 (WGS 84 / UTM Zone 52N)로 통일하였으며, 대구광역시와 경상북도 전역(울릉군·독도 제외)을 연구지역으로 설정하였다. 지형적 요인은 산불의 확산 경향과 화염의 강도에 영향을 미치는 주요 요인으로, 고도(digital elevation model, DEM), 경사(slope), 향(aspect), 곡률(curvature)의 네 가지 변수를 사용하였다. 기본 자료는 Copernicus GLO-30 DEM (30 m 해상도)을 이용하였으며, Google Earth Engine (GEE)에서 연구지역 경계에 맞추어 클리핑 후 각 지형 파생변수를 산출하였다. DEM은 지표의 절대 고도를 나타내며 산불의 연료 수분 함량과 바람의 흐름 방향에 영향을 미친다. 연구지역의 고도는 0–1,450 m 범위로 분포하며, 북부 및 동부 산악지대에서 높은 값을 보인다. Slope는 DEM의 고도차를 기반으로 계산된 기울기로, 경사가 급할수록 화염의 상향 확산이 빠르게 일어나 산불의 진행속도에 직접적인 영향을 미친다. Aspect는 사면의 주방향을 8방위(N, NE, E, SE, S, SW, W, NW)로 구분하여 일사 영향과 건조도 차이를 반영한다. Curvature는 지형의 오목(convex) 또는 볼록(concave) 형태를 나타내는 지표로, 양의 값은 능선부, 음의 값은 곡저부를 의미하며 화염 확산 방향 및 열집중 구역을 판단하는 보조지표로 사용되었다. 산림 요인은 산불의 착화 가능성과 연소 강도를 결정하는 연료 특성과 관련이 있으며, 국립산림과학원의 제5차 임상도(1:25,000)를 이용하여 경급(DMCLS_CD), 밀도(DNST_CD), 임상유형(FIFTH_FRTP) 세 가지 변수를 구축하였다. 모든 데이터는 임상도의 속성 정보를 기반으로 추출하였으며, 공간적 연속성을 확보하기 위해 Euclidean Distance (유클리드 거리) 분석을 수행하여 30 m 해상도의 래스터로 변환하였다. 경급(DMCLS_CD)은 흉고직경(DBH)에 따라 산림 발달 단계를 구분하며, 1은 치수(6 cm 미만), 2는 소경목(6–18 cm), 3은 중경목(18–30 cm), 4는 대경목(30 cm 이상)을 의미한다. 중·대경목 지역은 연료 축적이 많아 연소 강도가 높게 나타난다. 밀도(DNST_CD)는 교목층의 수관 피복률에 따른 산림의 조밀도를 나타내며, A (희소, 50% 이하), B (중간, 51–70%), C (밀, 71% 이상)의 3단계로 구분된다. 고밀도 산림은 화염 확산이 빠르며 피해 규모가 확대될 가능성이 크다. 임상유형(FIFTH_FRTP)은 수종 구성에 따른 임분 특성을 반영하는 변수로, 침엽수림(C), 활엽수림(H), 혼효림(M)으로 구분하였다. 침엽수림 지역은 수액 내 휘발성 물질이 많아 화재 착화와 확산에 취약하다. 인위적 환경 요인은 산불의 인위적 점화 가능성과 접근성 및 확산 경계를 반영하기 위해 선정하였으며, 하천까지의 거리(rivers proximity)와 도로까지의 거리(roads proximity)를 사용하였다. 하천 데이터는 HydroSHEDS (2025)에서 제공하는 고해상도 수계망을, 도로 데이터는 Geofabrik GmbH (2025)에서 제공하는 도로 네트워크를 이용하였다. 각 데이터는 연구지역을 기준으로 클리핑한 후 선형 피처(line feature)에 대해 Euclidean Distance 분석을 수행하여 픽셀 단위 거리값으로 변환하였다. 하천은 화염 확산을 저지하는 자연적 방화선 역할을 하며, 하천 주변은 상대적으로 습윤도가 높아 산불 위험이 낮은 지역으로 분류된다. 반면 도로는 인위적 점화 요인(human ignition source) 및 진화 접근 경로(emergency accessibility)를 반영하는 변수로, 도로 인근 지역에서 화재 발생 가능성이 높게 나타났다. 기후적 요인은 산림의 수분 상태, 대기 건조도, 풍력 확산 등 산불의 발생과 확산을 결정하는 핵심 기상 요소를 반영하였다. 강수량, 풍속, 수증기압(vapor pressure deficit, VPD)을 사용하였으며, 강수량과 VPD는 TerraClimate 데이터를 이용하여 2003–2020년 기간의 연평균값을 산출하였고, 풍속은 ERA5-Land 재분석 자료(ECMWF/ERA5_LAND/HOURLY)를 사용하였다. 풍속은 10 m 높이에서의 u, v 성분을 이용하여 벡터 크기로 계산하였다. 강수량은 산림 연료의 수분 공급 정도를, VPD는 대기의 건조도를, 풍속은 화염의 이동 방향과 확산 속도를 나타내며, 특히 강풍 구역에서는 산불 확산 위험이 높게 나타난다. 이러한 모든 변수는 GEE를 통해 공간적 일관성을 확보한 후 30 m 해상도로 리샘플링하여 분석에 활용하였다.
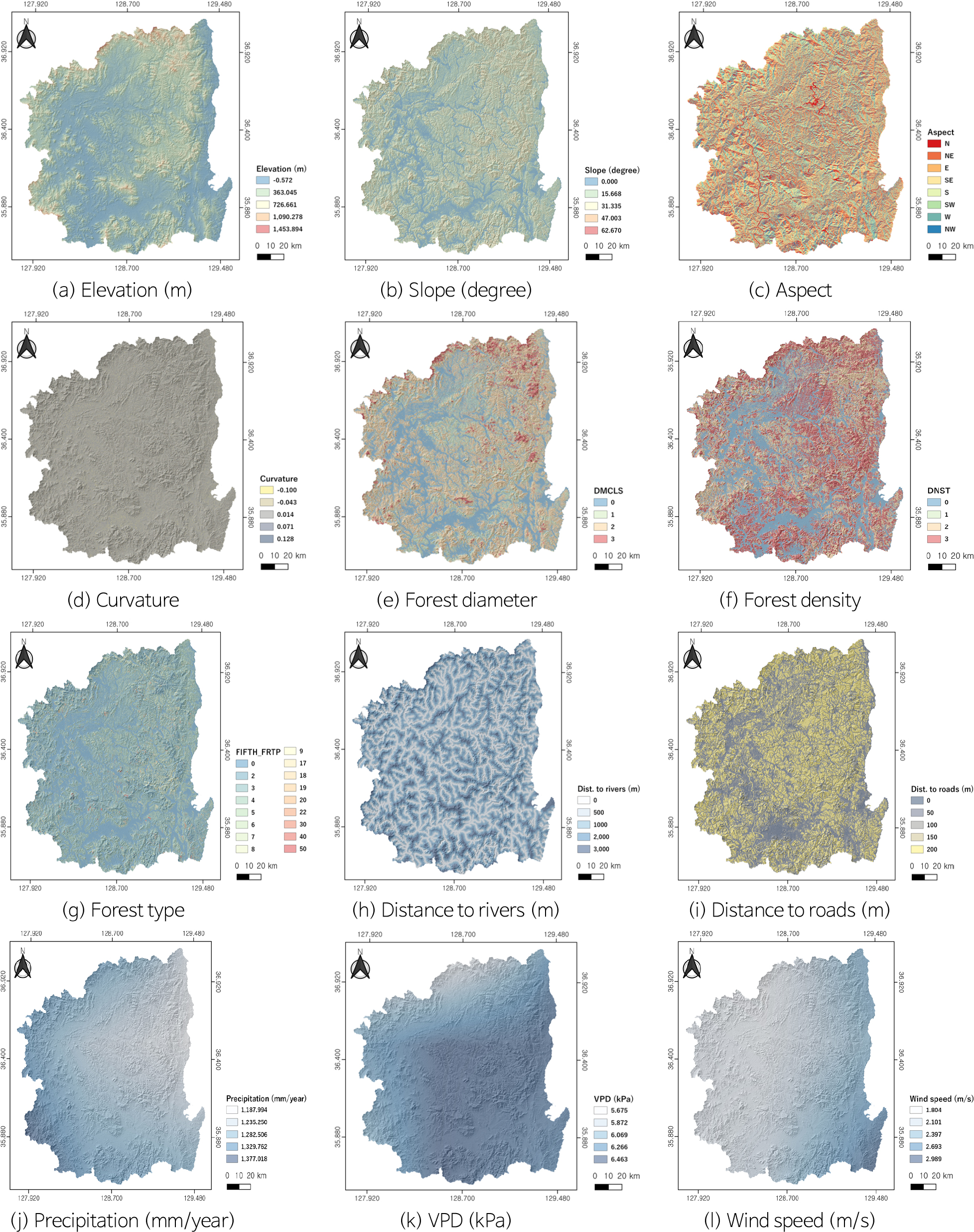
Fig. 1.
Spatial distribution of the environmental factors used for wildfire susceptibility modeling in the Daegu–Gyeongbuk region. (a) Elevation (m), (b) Slope (°), (c) Aspect, (d) Curvature, (e) Forest diameter (diameter class), (f) Forest density (density class), (g) Forest type, (h) Distance to rivers (m), (i) Distance to roads (m), (j) Precipitation (mm/year), (k) Vapor pressure deficit (VPD, kPa), and (l) Wind speed (m/s).
다중공선성 분석
AutoML에 사용된 입력 변수가 통계적으로 적절하며 다중공선성을 유발하지 않도록 하기 위해 체계적인 변수 선정 절차를 수행하였다. 먼저 Pearson 상관분석(Pearson’s correlation analysis)을 통해 변수 간 상관성을 검토하였다. 높은 상관관계는 변수 중요도 산정에 왜곡을 초래하고 모델의 해석 가능성을 저하시킬 수 있기 때문이다. 이후 다중공선성 여부를 보다 정밀하게 평가하기 위해 Tolerance (TOL)와 Variance Inflation Factor (VIF) 지표를 활용하였다.
TOL은 한 예측변수가 다른 예측변수들에 의해 설명되지 않는 분산의 비율을 나타내며, VIF는 다중공선성으로 인해 회귀계수의 분산이 얼마나 팽창되었는지를 정량화한다. 본 연구에서는 TOL 값이 0.1 미만이거나 VIF 값이 10을 초과하는 변수를 다중공선성이 존재하는 것으로 판단하고, 해당 변수의 제거 또는 통합 가능성을 검토하였다. 이러한 다단계 변수 검증 과정을 통해 최종적으로 선정된 인자들은 수문학적 타당성을 유지함과 동시에 통계적으로 독립적인 특성을 확보하였으며, 이를 통해 예측 모델의 안정성과 해석력을 향상시켰다. 최종 선별된 변수들은 이후 TPOT 기반 산불 취약성 예측 모델의 입력 요소로 활용되었다.
Geo-Similarity 기반 비화재 샘플링
대구·경북 지역을 대상으로 2003년부터 2020년까지 구축된 총 1,038개의 산불 발생지점을 기반으로, 동일한 개수(1,038개)의 비화재 지점(non-fire sample)을 Geo-Similarity 기반 샘플링(Geo-Similarity Sampling) 기법을 활용하여 구축하였다. Geo-Similarity Sampling은 화재 발생지점과 유사한 지리적·환경적 특성을 가지면서 실제로는 산불이 발생하지 않은 지역을 선택함으로써, 데이터 불균형을 완화하고 모델의 일반화 성능을 향상시키는 공간 통계 기반의 표본추출 기법이다(Xu et al., 2023). 우선, 연구지역 전체에 대해 12개의 공간변수를 동일한 해상도(30 m) 및 좌표계(EPSG:32652)로 정규화하였다. 이 변수들은 각각 지형적, 산림적, 인위적 환경, 기후적 요인을 대표하며, 모든 입력 변수는 3차원 배열(stack) 형태로 결합하였다. 이후 실제 화재 발생지점에 해당하는 위치에서 각 변수값을 추출하여, 평균(μ)과 표준편차(σ)를 계산하였다. 후보군 생성 단계에서는 전체 유효 픽셀중에서 화재점과 중복되지 않으며, 모든 변수에 유효값이 존재하는 위치만을 선별하였다. 이렇게 확보된 후보군 중에서 화재점 개수의 약 300배에 해당하는 임시 표본(pool)을 무작위(random seed = 42)로 선택하였다. 각 후보점에 대해 화재점 분포의 통계적 특성(μ, σ)을 기반으로 가우시안 유사도(Gaussian similarity)를 산정하였다. 이때 개별 변수 단위의 유사도는 다음 식으로 계산되며, 전체 변수에 대한 평균 유사도(S̄)를 통해 화재점과의 지리적 비유사도(geo-dissimilarity)를 추정하였다. 이후 공간적 편향(spatial bias)을 최소화하기 위해, 10 km × 10 km 크기의 격자망(grid)을 생성하고 각 격자 내에서 비유사도(D)가 높은 상위 5개(top-5) 후보를 우선 선정하였다. 이렇게 선택된 샘플 중 비유사도 기준으로 상위 1,038개 지점을 최종 비화재 샘플(absence sample)로 확정하였다. 이 절차는 공간적으로 균형 잡힌(spatially balanced) 분포를 보장함과 동시에, 화재 발생지점과의 과도한 근접성으로 인한 중복 학습(overfitting)을 방지한다. 이와 같은 Geo-Similarity 기반 비화재 샘플링은 단순 거리 기반(random, buffer-based) 부재표본 추출법에 비해 지형·기후·산림적 조건을 통합적으로 반영하므로, 산불 취약성 모델링 시 입력데이터의 대표성과 공간적 균형을 동시에 확보할 수 있는 장점이 있다. 따라서 본 연구에서 구축된 presence/absence 데이터셋은 AutoML 기반 산불 취약성 예측모델의 학습 입력자료로 활용되었다.
TPOT 기반 모델 탐색 및 최적화
TPOT은 유전 알고리즘(genetic algorithm, GA)에 기반한 AutoML 프레임워크로, 데이터 전처리, 변수 선택, 모델 학습 및 하이퍼파라미터 최적화 과정을 자동화한다(Nam et al., 2025). TPOT은 돌연변이(mutation), 교차(crossover), 선택(selection) 등 진화 연산을 반복 수행함으로써 다양한 조합의 머신러닝 파이프라인을 탐색한다. 각 파이프라인은 전처리(preprocessing), 스케일링(scaling), 특성 선택(feature selection), 분류기(classifier) 등의 단계로 구성되며, 초기에는 무작위로 생성된 파이프라인 집단이 교차검증(cross-validation)을 통해 성능을 평가받는다. 이후 상위 성능을 보인 파이프라인이 부모로 선택되어 자식 세대를 생성하며, 세대가 반복될수록 최적화된 모델 구조에 수렴한다. 본 연구에서는 TPOT을 활용하여 지형, 산림, 인위적 환경, 기후 요인 등으로 구성된 입력 변수를 바탕으로 산불 취약성 예측에 최적화된 모델 조합을 탐색하였다. 분류 성능 평가지표로는 ROC-AUC (area under the receiver operating characteristic curve)를 사용하였으며, 5-겹 교차검증(5-fold cross-validation)을 통해 일반화 성능을 검증하였다. 또한, TPOT의 구성 사전(configuration dictionary)을 수정하여 의사결정나무(Decision Tree), 랜덤포레스트(Random Forest), XGBoost 등 주요 트리 기반 알고리즘의 탐색 공간을 중점적으로 구성하였다. 각 세대의 인구(population)는 100으로 설정하였으며, 100세대(generations)에 걸쳐 진화 과정을 수행하였다.
모델 평가 기준
모델의 성능을 종합적으로 평가하기 위해 임계값 비의존 지표(threshold-independent metrics)와 임계값 의존 지표(threshold-dependent metrics)를 병행하여 활용하였다. 우선, ROC-AUC를 주요 평가 지표로 채택하였다. ROC-AUC는 분류 임계값에 영향을 받지 않으면서, 모델이 실제 산불 발생 지역(presence)과 비발생 지역(absence)을 얼마나 잘 구분하는지를 정량적으로 평가할 수 있는 강건한 지표이다. 이와 함께 여러 임계값 의존형 지표를 추가로 산출하여 분류 성능을 다각도로 검증하였다. Accuracy (정확도)는 전체 예측 중에서 올바르게 분류된 비율을 의미하며, Precision (정밀도)은 산불로 예측된 지점 중 실제로 산불이 발생한 비율을 나타낸다. Recall (재현율, 혹은 민감도)은 실제 산불 발생지 중에서 모델이 올바르게 탐지한 비율을 의미한다. 이 두 지표 간의 균형을 평가하기 위해, F1-Score (정밀도와 재현율의 조화평균)도 함께 계산하였다. 또한, 데이터의 불균형 문제를 고려하여 Matthews Correlation Coefficient (MCC)를 적용하였다. MCC는 혼동행렬(confusion matrix)의 네 가지 요소(true positive, false positive, true negative, false negative)를 모두 반영하기 때문에, 양성·음성 클래스 간의 불균형 상황에서도 균형 잡힌 평가가 가능하다. 결과적으로, ROC-AUC, Accuracy, Precision, Recall, F1-Score, MCC의 여섯 가지 평가 지표를 종합적으로 활용함으로써, 본 연구에서 개발된 AutoML 기반 산불 취약성 예측 모델의 판별능력(discriminative capacity)과 분류 신뢰도(classification reliability)를 정량적으로 평가하였다.
연구결과
다중공선성 분석 결과
모델 입력 변수의 통계적 타당성과 독립성을 확보하기 위해, Pearson 상관분석과 다중공선성 진단(VIF)을 수행하였다. 먼저 연속형 변수 8개(DEM, Slope, Curvature, Rivers, Roads, Precipitation, VPD, WindSpeed)에 대해 Pearson 상관계수를 산정하였다(Fig. 2). 분석 결과, 대부분의 변수 간 상관계수(|r|)는 0.6 미만으로 나타나 다중공선성 우려가 낮은 것으로 확인되었다. 특히 DEM과 Slope 간의 상관계수가 0.53으로 비교적 높게 나타났으나, 일반적으로 지형적 인자 간의 구조적 상관으로 간주할 수 있는 수준으로 판단된다. DEM과 Rivers 간에도 0.47의 중간 수준 상관이 관찰되었으며, 이는 하천의 형성과정이 지형적 고도와 밀접하게 연관되어 있는 것으로 판단된다. 반면, 기후 요인(VPD, WindSpeed, Precipitation)과 지형 변수 간에는 뚜렷한 음의 상관관계가 일부 나타났는데, 이는 고도가 증가함에 따라 기온과 수증기압 부족(VPD)이 변화하는 기후학적 특성이 반영된 결과로 해석된다.
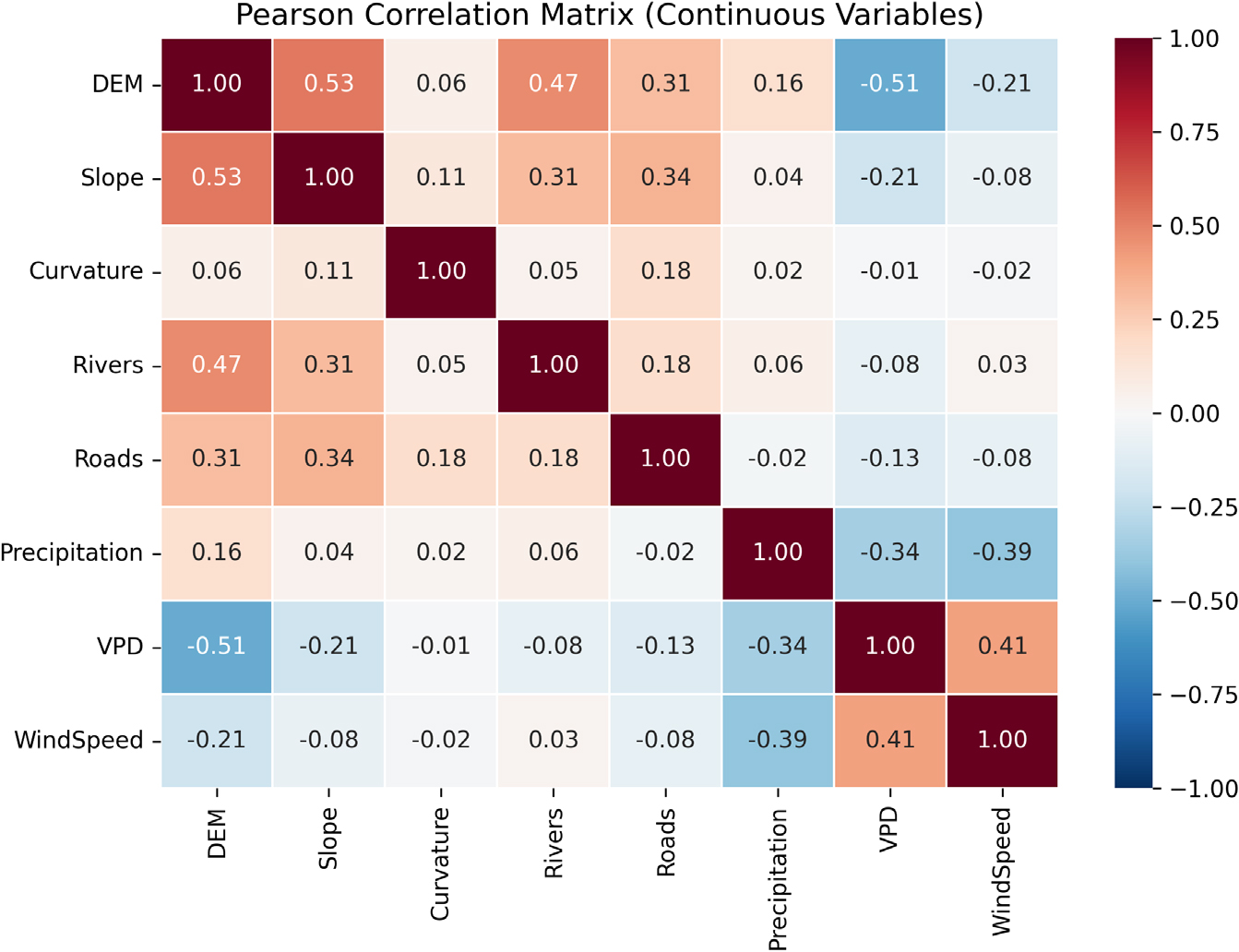
상관분석 결과를 바탕으로, 모델 입력 변수의 중복성을 정량적으로 검증하기 위해 다중공선성 분석(VIF–TOL)을 수행하였다(Table 1). 일반적으로 VIF 값이 10을 초과하거나, TOL 값이 0.1 미만인 경우 다중공선성이 존재한다고 판단한다. 본 연구의 결과에서 모든 변수의 VIF 값은 1.03–5.65 범위 내에 분포하였으며, TOL 값 또한 0.17–0.96으로 기준치를 충분히 상회하였다. 이는 입력 변수들 간의 상호 독립성이 통계적으로 확보되어 있으며, AutoML 학습 과정에서 특정 변수의 영향력이 과도하게 왜곡될 가능성이 낮음을 의미한다. 특히 산림 관련 인자인 DMCLS_CD (임상구분도)와 DNST_CD (임상밀도도)의 VIF 값이 각각 5.65 및 5.20으로 비교적 높은 편에 속하였으나, 이는 두 변수가 동일한 산림 공간 자료(1:25,000 임상도)에서 유래하였기 때문으로, 실제 모델링에서는 독립변수로서의 구분도를 유지할 수 있다고 판단된다. 그 외의 변수들은 모두 VIF < 2.5, TOL > 0.4로 나타나 다중공선성의 영향이 미미하였다. 종합적으로, Pearson 상관계수 분석과 VIF–TOL 검증을 통해 모든 환경변수가 통계적으로 독립적인 특성을 유지하고 있음을 확인하였다. 따라서 본 연구에서 사용된 12개 예측 인자(지형, 산림, 인위적, 기후 요인)는 AutoML 기반 산불 취약성 예측 모델의 입력 변수로 적절한 것으로 판단된다.
Table 1.
Multicollinearity diagnostics for the conditioning factors used in the wildfire susceptibility modeling
TPOT 기반 산불 취약성 평가
산불 취약성 예측을 최적화하기 위해 본 연구에서는 TPOT 기반 AutoML 기법을 적용하여 GaussianNB, Random Forest, XGBoost의 세 가지 분류 모델을 구축하였다(Fig. 3). TPOT은 유전 알고리즘 기반 탐색을 통해 전처리–특징선택–분류기의 조합을 자동으로 최적화하며, 반복적 진화 과정을 통해 가장 높은 예측 성능을 갖는 파이프라인을 도출하였다. 먼저, GaussianNB 모델은 단일 Gaussian Naïve Bayes 연산자로 구성된 단순 확률 구조를 가지며, 내부 교차검증(cross-validation, CV) 점수는 0.973으로 확인되어 기본적인 분류 성능을 확보하였다. Random Forest 모델은 MinMaxScaler 전처리와 함께 부트스트랩(bootstrap=True), 지니 계수(criterion=‘gini’), 최대 특징 비율(max_features=0.2), 최소 분할 샘플수(min_samples_split=4), 최소 리프 샘플수(min_samples_leaf=8), 트리 수(n_estimators=100) 등의 파라미터가 자동 설정되었으며, 내부 CV 점수는 0.996으로 세 모델 중 가장 우수하였다. XGBoost 모델은 learning_rate=0.001, max_depth=9, min_child_weight=7, subsample=0.45, n_estimators=100 등의 하이퍼파라미터로 최적화되었으며, CV 점수는 0.978로 높은 일반화 성능을 보였다. 공간적 산불 취약성 분포(Fig. 3a–c)는 대체로 경북 동부 및 남동부 산악 지역, 특히 경사도가 크고 산림밀도가 높은 지역에서 높은 취약성을 보였다. 세 모델 모두 고도, 경사, 산림 밀도, 낮은 습도(VPD가 높은 지역) 등 산불에 취약한 환경적 조건에서 높은 취약성 등급을 예측하였다. 모델의 외부 검증 결과(Fig. 3d), ROC (receiver operating characteristic) 곡선과 AUC 지표를 활용한 분류 정확도 비교에서 TPOT–Random Forest가 AUC = 0.998로 가장 높은 예측력을 보였으며, TPOT–GaussianNB는 0.985, TPOT–XGBoost는 0.975로 뒤를 이었다. 이 결과는 Random Forest 기반 모델이 산불 발생과 비발생 지역을 가장 효과적으로 구분함을 의미한다. 특히 TPOT–XGBoost 모델은 고위험 지역을 상대적으로 더 집중적으로 식별하였으며, TPOT–Random Forest 모델은 저·고위험 지역 간의 균형 잡힌 공간 분류를 보여주었다. 모든 모델에서 취약성 등급이 높을수록 실제 산불 발생지점과의 공간적 일치도가 증가하는 경향을 보였으며, 이는 Geo-Similarity 기반 샘플링과 AutoML의 결합이 데이터 불균형 문제를 완화하고, 산불 위험지도 작성의 공간적 신뢰도를 향상시키는 데 효과적임을 입증한다.
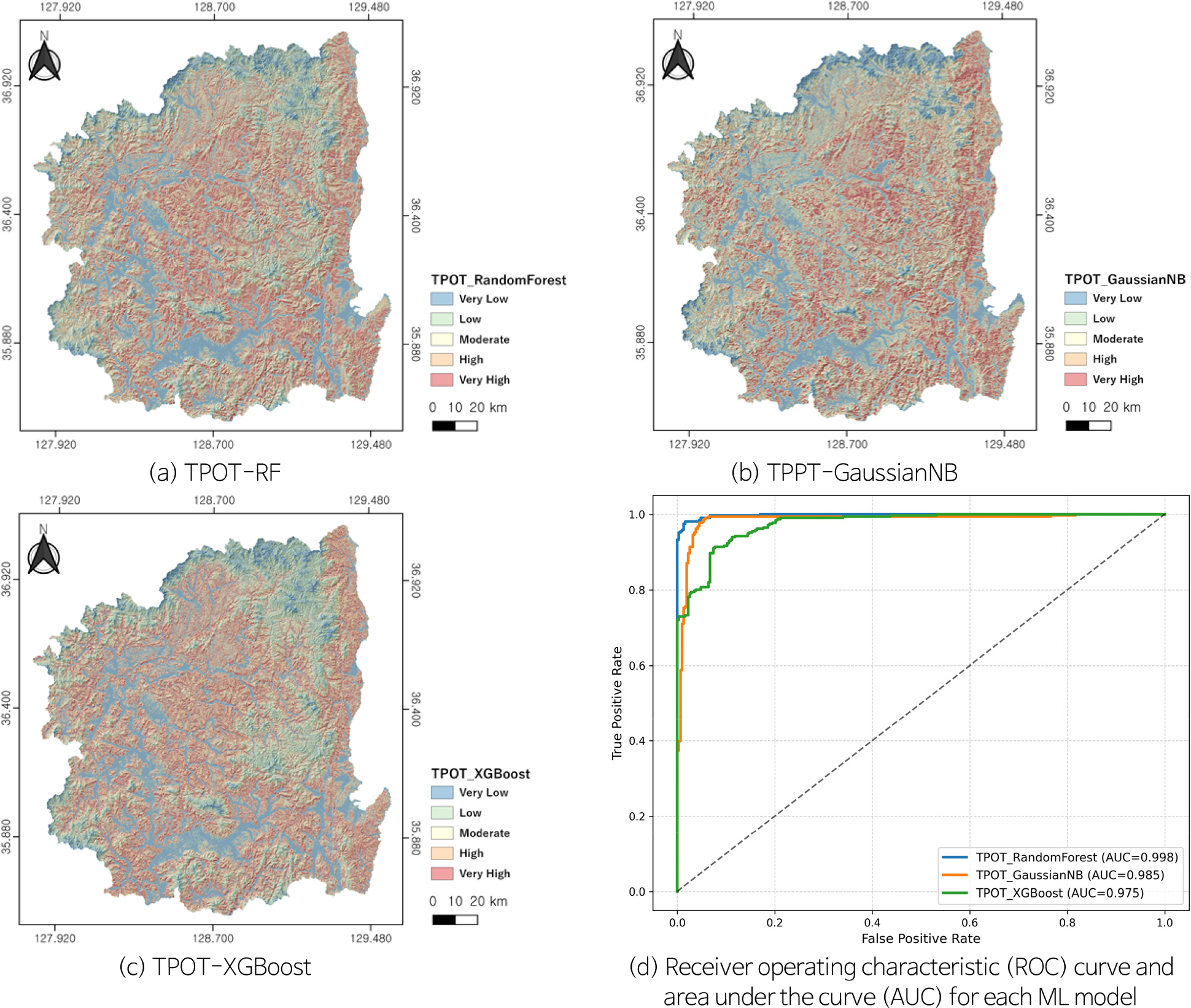
모델 성능 및 SCAI 분석 결과
모델별 성능 분석 결과(Table 2), Random Forest 모델이 가장 우수한 예측 성능을 보였다(AUC = 0.998, ACC = 0.981, F1 = 0.981, MCC = 0.961). 이는 다양한 결정트리의 앙상블 구조를 통해 변수 간 비선형 관계를 효과적으로 학습하고 과적합을 방지한 결과로 해석된다. GaussianNB 모델은 AUC 0.985, ACC 0.950으로 전반적으로 안정적인 분류 성능을 보였으며, 단순 확률 분포 기반 알고리즘 특성상 복잡한 상호작용을 완벽히 반영하지는 못했지만, 계산 효율성이 높고 전반적인 예측 정확도 또한 우수하였다. XGBoost 모델은 AUC 0.975, ACC 0.912로 세 모델 중 상대적으로 낮은 값을 보였으나, 비선형 경계의 복잡한 패턴을 부분적으로 반영하는 데 강점을 보였다. 세 모델 모두 Accuracy와 F1-score가 0.9 이상으로 나타나, Geo-Similarity 기반 샘플링을 통해 균형 잡힌 학습 데이터셋이 확보되었음을 시사한다.
Table 2.
Performance of TPOT-based classifiers for wildfire susceptibility modeling
| Model | AUC | Accuracy | Precision | Recall | F1-score | MCC |
| TPOT_GaussianNB | 0.985 | 0.950 | 0.967 | 0.932 | 0.949 | 0.901 |
| TPOT_RF | 0.998 | 0.981 | 0.981 | 0.981 | 0.981 | 0.961 |
| TPOT_XGB | 0.975 | 0.912 | 0.910 | 0.913 | 0.912 | 0.823 |
예측된 산불 취약성 지도에 대한 공간분류정확도지수(SCAI)는 모델의 공간적 신뢰성을 정량적으로 평가하기 위해 수행되었다(Table 3). SCAI는 각 취약성 등급별 면적 비율 대비 실제 산불 발생 비율의 비를 통해 산정되며, 값이 작을수록 실제 산불이 해당 등급에 더 집중되어 있음을 의미한다. GaussianNB 모델의 SCAI 값은 ‘매우 높음(very high)’ 등급에서 0.611, ‘높음(high)’ 등급에서 0.749로 나타나, 상위 위험 지역에서 실제 산불 분포와의 공간적 일치도가 양호하게 나타났다. Random Forest 모델은 ‘매우 높음’ 등급에서 SCAI 0.468로 세 모델 중 가장 낮은 값을 보여, 가장 높은 공간적 예측 신뢰도를 확보하였다. XGBoost 모델 또한 ‘매우 높음’ 등급에서 0.463으로 유사한 경향을 보였으나, 저위험 지역(‘매우 낮음’)의 SCAI 값이 상대적으로 높아 공간적 집중도가 다소 낮은 것으로 나타났다. 모든 모델에서 등급이 높아질수록(즉, 산불 위험이 증가할수록) SCAI 값이 감소하는 뚜렷한 경향을 보였다. 이는 모델이 산불 발생 가능성이 높은 지역을 효과적으로 식별하고 있음을 의미한다. 특히 RF 모델은 고위험 등급에서의 SCAI 저하폭이 크고, 저위험 지역에서의 오탐률이 낮아 전반적으로 가장 안정적이고 신뢰성 있는 공간 분류 성능을 보였다. 종합적으로, 본 연구의 결과는 Geo-Similarity 샘플링과 AutoML 결합 접근법이 데이터 불균형 문제를 완화하고, 수작업 하이퍼파라미터 조정 없이도 높은 정확도와 공간적 일치성을 확보할 수 있음을 입증한다. 이러한 결과는 산불 취약성 지도 작성 및 방재 의사결정 지원 시스템 구축에 효과적으로 활용될 수 있을 것이라 판단된다.
Table 3.
Spatial classification accuracy index (SCAI) results for wildfire susceptibility classes across TPOT-based models
토 론
Geo-Similarity 샘플링의 효과
Geo-Similarity 샘플링은 발화 지역과 유사한 환경적 특성을 갖지만 실제로는 발화하지 않은 지점을 통계적으로 선별하여 비발화 데이터를 구축함으로써, 데이터 불균형 문제를 효과적으로 완화하였다. Table 2의 결과에서 확인할 수 있듯이, 세 모델 모두 Accuracy 0.91 이상, F1-score 0.91 이상, AUC 0.97 이상의 높은 분류 성능을 보였으며, 이는 학습 데이터의 품질이 향상되고 발화·비발화 패턴이 보다 명확히 구분되었음을 보여준다. 특히 본 연구의 Geo-Similarity 샘플링은 임계값(threshold)을 임의로 설정하지 않고, 발화 지역의 환경 변수 분포(평균 μ, 표준편차 σ)를 기반으로 한 가우시안 유사도(Gaussian similarity) 함수를 적용하였다. 이를 통해 주관적 판단에 의한 임계값 설정을 배제하고, 데이터에 내재된 통계적 특성을 반영한 객관적 샘플링 절차를 구현하였다. 또한 격자 단위(10 km) 내에서 상위 유사도 점수를 가지는 Top-N 지점을 선택함으로써, 특정 지역에 비발화 샘플이 과도하게 집중되는 문제를 방지하고, 공간적으로 균형 잡힌 학습 데이터 구성이 가능하도록 하였다. 이러한 방법론적 특성은 모델의 공간적 예측 신뢰성 향상으로 이어졌다. SCAI 분석 결과(Table 3)에 따르면, 세 모델 모두 취약성 등급이 높아질수록(high → very high) SCAI 값이 점진적으로 감소하는 일관된 경향을 보였다. 특히 ‘매우 높음(very high)’ 등급에서 SCAI 값이 0.46–0.61 범위로 낮게 나타나, 모델이 실제 산불 발생 지역과 높은 공간적 일치도를 보임을 확인할 수 있었다. 반면, ‘매우 낮음(very low)’ 등급에서는 상대적으로 높은 SCAI 값을 보여, 위험도가 낮은 지역을 명확히 구분하고 있음을 시사한다. 결과적으로, Geo-Similarity 샘플링은 기존의 임의적 임계값 설정이나 단순 거리 기반 샘플링 방식의 한계를 보완하면서, 데이터의 통계적 특성과 공간적 균형을 동시에 고려하는 효율적인 접근법으로 평가된다. 본 연구 결과는 이러한 샘플링 전략이 산불 취약성 평가에서 데이터 품질과 공간적 일관성을 동시에 확보할 수 있는 실질적인 대안이 될 수 있음을 보여주며, 향후 산사태·홍수 등 공간적 패턴이 뚜렷한 재해 예측 연구에도 적용 가능성을 제시한다.
AutoML (TPOT) 기반 모델의 성능 해석
TPOT은 진화적 알고리즘을 이용해 수천 개의 파이프라인을 탐색하며 최적의 조합을 자동 도출한다. 본 연구에서는 GaussianNB, Random Forest, XGBoost의 세 모델이 최종 선택되었으며, 이 중 Random Forest 모델이 AUC = 0.998, ACC = 0.981, F1 = 0.981로 가장 높은 분류 성능을 보였다. RF 모델의 우수한 성능은 앙상블 구조를 통한 과적합 방지 및 변수 간 비선형 관계 학습 능력에 기인한다. 반면 GaussianNB는 확률 기반 단일 분류기임에도 불구하고 비교적 높은 예측력(AUC = 0.985)을 보여, TPOT이 단순 모델도 데이터 특성에 맞게 최적화할 수 있음을 확인하였다. XGBoost는 다소 낮은 성능을 보였으나(ACC = 0.912), 높은 해석 가능성과 학습 속도 면에서 실용적인 장점을 가진다. 이러한 결과는 AutoML 접근법이 수작업 기반의 하이퍼파라미터 조정보다 효율적이며, 복수의 모델 구조를 자동으로 탐색하여 합리적 근거를 가진 최적 해를 제공할 수 있음을 시사한다.
SCAI를 통한 공간적 일치도 평가
SCAI는 모델의 공간적 예측 일관성을 정량적으로 평가하기 위한 지표로, 낮은 값일수록 실제 산불 발생 분포와의 일치도가 높음을 의미한다. 본 연구 결과, 모든 모델에서 등급이 높아질수록(high → very high) SCAI 값이 감소하는 일관된 패턴이 확인되었다. 특히, Random Forest 모델의 ‘매우 높음(very high)’ 등급에서 SCAI = 0.47, GaussianNB는 SCAI = 0.61, XGBoost는 SCAI = 0.46으로 나타나, RF (Random Forest)와 XGB (Extreme Gradient Boosting)가 높은 공간 예측 신뢰도를 확보하였다. 이러한 결과는 Geo-Similarity 기반 샘플링이 데이터의 지역적 패턴을 잘 반영하여, 예측 결과의 공간적 왜곡을 줄이고 실제 발화 지역과의 공간적 일치성을 향상시켰음을 보여준다.
한계점 및 향후 연구 방향
본 연구는 AutoML과 Geo-Similarity 샘플링을 결합한 사례로서 의미가 있으나, 몇 가지 한계도 존재한다. 첫째, 본 연구의 기후 인자는 평균(2003–2020년) 연평균 자료를 기반으로 산출되어, 계절별 변동성(seasonal variability) 반영이 제한적이었다. 향후에는 봄철(3–5월) 중심의 계절별 NDVI (Normalized Difference Vegetation Index), VPD, 풍속, 강수량 등 고해상도 시계열 데이터를 활용한 동적 취약성 분석이 필요하다. 둘째, Geo-Similarity의 가우시안 거리 기반 유사도는 각 변수 간 독립성을 가정하므로, 변수 간 상호작용이 존재하는 경우에는 오차가 발생할 수 있다. 이를 보완하기 위해 향후 연구에서는 비선형 유사도 함수(Kernel similarity) 또는 Mahalanobis Distance 기반의 다변량 공간 유사도 모델을 적용할 계획이다. 셋째, 본 연구는 30 m 공간해상도의 raster 데이터를 사용하였으나, 향후 Sentinel-1/2, LiDAR (light detection and ranging) 기반 고해상도 지형 자료(≤10 m)를 이용하면 소규모 산불 위험지대까지 정밀한 예측이 가능할 것으로 기대된다. 종합적으로, 본 연구는 AutoML과 Geo-Similarity Sampling의 융합이 산불 취약성 평가의 자동화와 신뢰성 향상에 실질적인 기여를 할 수 있음을 실증적으로 입증하였다. 향후 이러한 프레임워크는 산불뿐 아니라 산사태, 홍수, 토석류 등 다중 재해의 공간 예측 및 위험 관리 체계에도 확장 적용될 수 있을 것이다.
결 론
GeoAI 기반 AutoML 접근법을 활용하여 대구·경북 지역의 산불 취약성을 정량적으로 평가하고, Geo-Similarity 샘플링을 통해 공간적 불균형 문제를 개선한 새로운 산불 예측 프레임워크를 제시하였다.
첫째, Geo-Similarity 기반 샘플링을 통해 발화 지역과 유사한 지리·기후·산림 환경 조건을 가지는 비발화 지점을 정량적으로 구축함으로써, 기존의 무작위 샘플링 방식보다 데이터 불균형을 효과적으로 완화하였다. 이는 모델 학습 시 과대적합을 방지하고, 저위험 지역에서의 오탐(false positive)을 감소시키는 데 기여하였다.
둘째, TPOT 기반 AutoML을 적용하여 GaussianNB, Random Forest, XGBoost의 세 가지 모델을 자동으로 탐색·최적화한 결과, Random Forest 모델이 AUC 0.998, ACC 0.981로 가장 우수한 분류 성능을 보였다. 이는 AutoML 접근법이 수작업 기반의 모델 선택 및 하이퍼파라미터 조정보다 높은 효율성과 예측 정확도를 동시에 확보할 수 있음을 의미한다.
셋째, SCAI 분석 결과, 세 모델 모두 취약성 등급이 높아질수록 SCAI 값이 감소하는 경향을 보였으며, 특히 Random Forest 모델은 ‘매우 높음(very high)’ 등급에서 SCAI 0.47로 가장 높은 공간적 일치도를 나타냈다. 이는 Geo-Similarity 샘플링이 실제 산불 발생 분포의 공간 패턴을 효과적으로 반영하고, 모델 예측의 공간적 신뢰성을 향상시켰음을 입증한다.
넷째, 본 연구에서 제안한 Geo-Similarity + AutoML 통합 프레임워크는 복잡한 변수 간 상호작용을 자동으로 최적화하고, 해석 가능한 공간 예측 결과를 도출함으로써 향후 산불 방재정책 수립 및 위험지도 제작에 실질적인 활용 가능성을 제시한다.
향후 연구에서는 계절별·시간대별 환경 변수(예: 봄철 NDVI, VPD, 풍속)의 시계열 특성을 반영한 동적 산불 예측 모델을 개발하고, 고해상도 LiDAR 및 SAR (synthetic aperture radar) 기반 지형자료를 결합하여 국지적 발화 위험도 평가의 정밀도를 높일 필요가 있다. 또한, GeoAI 기반의 자동화된 산불 취약성 평가 체계를 제시함으로써, 산불 예측의 객관성, 공간적 신뢰성 등을 향상시킨 사례로서 의미가 있으며, 향후 산사태·홍수 등 복합 재해 예측 연구에도 확장 적용이 가능할 것으로 판단된다.
