

서 론
비탈면은 도로, 철도, 산업시설 등 다양한 사회기반시설의 안전과 직결되는 핵심 인프라 요소로서, 그 안정성 확보는 공공 안전과 사회적 비용 절감의 관점에서 중요한 과제이다(Kim et al., 2011; Lee et al., 2019). 우리나라의 급경사지 지형, 계절적 강수 집중, 국지성 호우 및 지진과 같은 자연재해는 비탈면 붕괴 위험을 상시적으로 높이고 있으며, 실제 붕괴 사고는 인명 피해와 재산 손실뿐 아니라 교통·물류망의 마비, 복구 비용 증가 등 광범위한 사회·경제적 파급효과를 초래한다(Park et al., 2006). 이러한 이유로 도로비탈면의 안정성 확보는 국가적 차원에서 필수적인 관리 과제이며, 이를 위해 다양한 대책공법이 현장에서 적용되고 있다(MLTMA, 2011).
그러나 현장의 공법 선정은 여전히 조사자의 경험과 직관에 크게 의존하고 있으며, 동일한 조건에서도 공법이 달라지는 경우가 발생한다. 이는 구조·지형·지질 등 다양한 요인들이 공법 선택에 복합적으로 영향을 미침에도 불구하고, 이를 체계적으로 정량 분석한 연구가 부족하기 때문이다. 기존 연구는 주로 단일 변수 효과나 위험등급 산출에 집중해 왔으나, 다변량 상호작용 효과는 충분히 반영되지 못했다.
한편, 도로비탈면관리시스템(Cut Slope Management System, CSMS) 기초조사 데이터는 전국 도로 비탈면의 구조적 요인(길이, 높이, 경사 등), 지형·환경 요인(상부 경사, 이격거리, 계곡부 여부 등), 지질·토층 특성(지질 분류, 토층심도 등)과 같은 다양한 범주의 정보를 포괄하고 있으며, 이는 대책공법 선정 요인을 분석할 수 있는 대표적 데이터 자원이다(KICT, 2019). 그러나 이와 같은 전국 단위 데이터가 존재함에도 불구하고, 이를 공법 선정에 직접적으로 활용하는 정량적 분석·예측 모델은 아직 확립되지 않았다.
이에 본 연구는 CSMS 기초조사 데이터를 활용하여 비탈면 붕괴 요인이 대책공법 선정에 미치는 영향을 다변량적으로 분석하는 것을 목적으로 한다. 구체적으로, 첫째 비선형·상호작용 구조를 반영하는 XGBoost (eXtreme Gradient Boosting) 알고리즘(Chen and Guestrin, 2016)을 통해 변수 예측 기여도를 산정하고, 둘째 트리 모형에 대해 정확 해석이 가능한 SHAP (SHapley Additive exPlanations, TreeSHAP) 기법(Mosca et al., 2022)을 적용하여 개별 변수의 기여도를 도출하였다. 셋째, Goodman-Kruskal’s λ (Goodman and Kruskal, 1954)를 활용해 변수와 결과 간 연관도를 평가하였으며, Spearman 상관분석(Myers and Sirois, 2004)을 통해 세 기법 간 일관성을 검증하고, SHAP 상호작용 분석을 통해 복합적 요인 상호작용이 공법 선택에 미치는 추가적 영향을 확인하였다.
이러한 다변량 분석 접근법을 통해 본 연구는 단일 기법의 해석 한계를 보완하고, 단일 변수 중심 해석을 넘어 복합적 요인 상호작용을 고려할 수 있다는 점에서 기존 연구와 차별성을 갖는다. 특히 머신러닝 기반 기법과 통계적 해석 기법을 결합하여 변수 예측 기여도, 연관도, 변수 간 상호작용을 통합적으로 제시한 점은 국내외 연구에서 찾아보기 어렵다. 본 연구는 현장 경험 중심의 의사결정을 보완할 수 있는 데이터 기반 기준을 마련하여, 공법 선정 과정의 객관성과 일관성을 높이고, 향후 관리 정책 수립과 예산 활용의 효율성 향상에 기여하고자 한다.
이론적 배경
국내에서는 도로비탈면관리시스템의 기초조사 데이터를 이용해 주요 요인 간 관계를 분석한 연구가 다수 보고되었다. 예를 들어, Cramér’s V 상관계수나 카이제곱 검정을 이용해 비탈면 종류-풍화도, 붕괴 이력-붕괴 유형, 비탈면 형상-뜬돌과 같이 높은 상관관계를 보이는 요인을 도출한 사례가 있다(Kim and Kim, 2024). 그러나 이러한 접근은 변수 간 정량적 연관성을 파악하는 데 유용하지만, 상관계수만으로는 변수의 예측 기여도나 다변량 상호작용 효과를 충분히 설명하기 어렵다는 문제점을 가지고 있다(Akoglu, 2018).
CSMS에서는 현재까지 전문가 판단에 기반한 위험 등급 산정이 주로 이루어져 왔다. 일부 연구에서는 로지스틱 회귀나 Random Forest와 같은 지도학습 기법을 적용하여 위험등급을 자동 예측하려는 시도가 있었으며, 이 과정에서 풍화도, 붕괴 이력, 경사 등의 변수가 높은 예측력을 보였다. 그러나 국내외 기존 문헌에서 설명 가능한 인공지능(XAI) 기법을 위험등급 또는 공법 선정 예측에 체계적으로 적용한 사례는 제한적이었다. 2020년 이후에는 SHAP 등을 결합한 비탈면 붕괴 및 산사태 취약도 연구가 활발히 보고되고 있는데, 지형·지질·수문 요인의 공간적 이질성을 SHAP-XGBoost로 분석한 사례가 있으며(Zhang et al., 2023), 한국 청주 지역에 CNN (convolutional neural network)을 적용한 뒤 SHAP으로 전역·국지 단위의 해석 가능성을 제시한 연구도 보고되었다(Pradhan et al., 2023).
대책공법 선정 예측은 위험 분석의 실무적 종착점으로, 구조적 안정성 확보를 위한 시공 방법을 결정하는 과정이다. CSMS 기초조사 데이터와 앙상블 기반 알고리즘인 Random Forest, XGBoost, LightGBM, CatBoost 및 딥러닝 DNN (deep neural network), TabNet을 비교하여 7종의 대책공법을 예측한 연구가 있다(Kim and Kim, 2024). 분석 결과, 앙상블 기법이 전반적으로 높은 성능을 보였으며, 이는 범주형 변수가 많은 CSMS 데이터의 특성과 트리 기반 모델의 적합성이 반영된 결과로 해석되었다. 해외 연구에서도 범주형 데이터의 공법·등급 예측에 앙상블 기법이 효과적이라는 보고가 있으며(Prokhorenkova et al., 2018; Saqlain et al., 2019), 트리 기반 모델은 변수 예측 기여도 산출과 해석 가능성 제공 측면에서 강점이 있다.
기존 연구들은 붕괴 요인 분석이나 공법 예측을 개별적으로 수행한 경우가 대부분이었으며, 변수 예측 기여도와 상호작용 효과를 통합적으로 제시한 사례는 드물다. 특히 XGBoost와 SHAP을 결합하여 공법 선정 요인의 상호작용 효과를 동시에 해석하고, Goodman-Kruskal’s λ으로 공법 연관도를 병행 평가하고, Spearman 순위상관으로 기법 간 일관성을 검증한 구성은 국내외에서 드물다. 이에 본 연구는 CSMS 기초조사 데이터를 바탕으로 변수 예측 기여도-공법 연관도-변수 간 상호작용을 통합적으로 제시함으로써 기존 연구의 한계를 보완하고, 현장 의사결정을 위한 데이터 기반 근거를 제공한다.
데이터 분석
도로비탈면관리시스템
도로비탈면관리시스템은 국토교통부가 위탁하고 한국건설기술연구원(KICT)과 국토안전관리원이 공동으로 운영하여 일반국도를 따라 존재하는 도로비탈면을 선제적으로 관리하기 위한 체계이다(KICT, 2019). 이 시스템은 국도변의 모든 깎기 비탈면에 대해 기본 현황, 위험도 평가, 정밀 조사 및 대책 수립 정보를 데이터베이스화하여 체계적으로 관리하며, 연차별 유지·보수 계획 수립, 전문가에 의한 대책방안 마련, 위험등급 산정, 투자우선순위의 결정 등의 업무를 수행하고 있다. CSMS 데이터는 크게 기초조사 데이터와 정밀조사 데이터로 구분된다. 본 연구에서는 기초조사 데이터를 활용하였으며, 기초조사 데이터는 전국 국도변의 모든 깎기 비탈면을 대상으로, 위치·구조·지질·환경 조건 등 기본 특성을 전수조사하여 기록한 데이터로 구성되어 있다.
데이터 구성
본 연구에서 사용된 CSMS 기초조사 데이터는 2006년부터 2024년까지 수집된 30,543개 비탈면에 대한 기초조사 데이터로, Table 1에 나타난 바와 같이 비탈면 기본 정보(코드, 위치 등), 길이, 최대 높이, 경사, 상부 경사, 이격거리, 소단 개소수 등의 연속형 정보와 비탈면 종류, 주변 지형, 지하수, 풍화도, 불연속면 방향성 등의 비탈면 특성 및 필요대책공법 등과 같은 범주형 변수로 구성된다. 변수 표기는 처음 등장 시 한글 정식 용어에 영문 풀네임과 약어(내부 코드)를 표기하고 이후에서는 약어만 사용한다. 예측 대상인 대책공법(countermeasure method, measure)을 제외하고, 사용된 설명변수는 기능적 특성에 따라 네 범주로 구분한다. 구조·지질 변수에는 비탈면 종류(material class, materialc), 풍화도(weathering degree, weathering), 암반 형태(bedrock shape, bshape), 불연속면 방향성(discontinuity directionality, dirdisc), 불연속면 특성(type of discontinuity, tdisc), 낙석(rockfall, vrockf), 뜬돌(loose rock blocks, rrocks) 등이 포함되며, 이는 비탈면의 물리적·지질학적 특성을 나타낸다. 환경·수리 변수에는 지하수(groundwater, gwater), 이격거리(separation distance, sdistance), 계곡부(valley, valley) 등이 포함되어 비탈면이 위치한 주변 환경과 수리학적 조건을 반영한다. 위험·이력 변수에는 붕괴 이력(collapse history, chistory), 붕괴 유형(type of failure, tfail) 등이 있으며, 이는 비탈면의 위험 수준과 과거 붕괴 경험을 나타낸다. 형상 변수에는 비탈면 형상(slope shapes, shapes), 측면 형상(slope sides, sides), 길이(length, length), 최대 높이(maximum height, height), 경사(angle, angle), 상부경사(upper angle, uangle), 소단 개소수(number of berms, nberm), 토층심도(depth of soil, dsoil) 등이 포함되며, 이는 비탈면의 기하학적 형태를 설명한다. 이와 같은 변수 분류는 수행하는 XGBoost, SHAP, Goodman-Kruskal’s λ 분석에서 각 변수 영역이 대책공법 선정에 미치는 기여도와 연관도를 해석하는 중요한 기반이 된다.
Table 1.
Composition of CSMS basic investigation
Fig. 1은 연속형 설명변수를 사전에 부여한 분위(정수 1–8; 1 = Q1, …, 8 = Q8)로 표현하고, 각 변수에서 실제로 존재하는 최대 코드값 K까지만 누적 막대를 채워서 Q1–QK 분포를 합본으로 제시한 것이다. 본 그림은 전체 30,543개 표본을 대상으로 하며, 변수별로 최대 코드(등급 수)가 달라서(예: tdisc는 Q8까지, 일부 변수는 Q6–Q7 수준에서 끝남) 각 변수의 최대 코드까지만 누적한 분포를 보여준다. 형상 변수(길이·최대 높이·경사·상부경사 등)는 상위 코드의 비중이 비교적 크게 나타나는 경향이 있다. 즉, 규모가 크거나 경사가 큰 비탈면이 더 많다고 볼 수 있어, 해당 구간에서는 보강 계열(앵커·록볼트·격자보)의 우선 고려가 필요할 것으로 보인다. 지질·수리 계열에서는 풍화도·불연속면 특성의 불리한 코드가 많을수록 강도가 약해질 수 있어 표면보호 및 보강 필요도가 커진다고 본다. 또한 지하수·계곡부(valley)의 높은 코드 분포는 물이 고이거나 물길이 모여 불리한 조건이 생길 수 있음을 나타내므로, 배수 및 유로 정비를 우선 적용하는 것이 좋아보인다. 이 같은 가정은 결과 절에서 XGBoost-SHAP 변수 기여도와 Goodman-Kruskal’s λ로 연관도를 확인한다.
본 연구에서 분석을 위해 사용되는 대책공법은 Table 2와 같이 총 7종이며, 각 공법은 비탈면의 상태와 위험 요인에 따라 선택하였다. 현상태 유지(status quo)는 약 57%로 가장 큰 비중을 차지하며, 비탈면의 안정성이 양호하고 추가 보강이 필요하지 않은 경우에 적용되며 주기적인 점검을 통해 유지관리를 수행하고 있다. 활동하중경감(active load inducing method)은 3.6%로 비탈면 내에서 활동을 일으킬 수 있는 암괴나 토사를 미연에 제거하여 안정성을 높이는 방법으로, 절취, 면정리 등이 이에 해당된다. 활동억제(resistance method)는 5.9%로 비탈면의 변위를 억제하기 위해 직접적인 구조적 제어를 가하는 방식으로, 앵커, 락볼트, 옹벽 등이 해당된다. 낙석제어(rockfall control method)는 약 21%로 비탈면에서 발생가능한 낙석으로 인한 피해를 방지하기 위해 낙석방지옹벽, 낙석방지망, 낙석방지울타리 등 보호 시설을 설치하는 방법이다. 표면 보호(surface control method)는 약 3%로 비탈면 표면의 침식과 풍화를 억제하고 안정성을 유지하기 위해 식생녹화, 숏크리트, 격자블록 등을 시공하는 방법이다. 수리제어(hydraulic control method)는 역시 약 3%로 비탈면 내·외부의 수분 흐름을 조절하여 침투수로 인한 비탈면 약화를 방지하는 방법으로, 배수관, 집수정, 수평배수공 등이 포함된다. 기타(other)는 0.2%로 앞선 범주에 속하지 않거나 현장 여건에 맞춰 특수 설계된 공법을 의미한다.
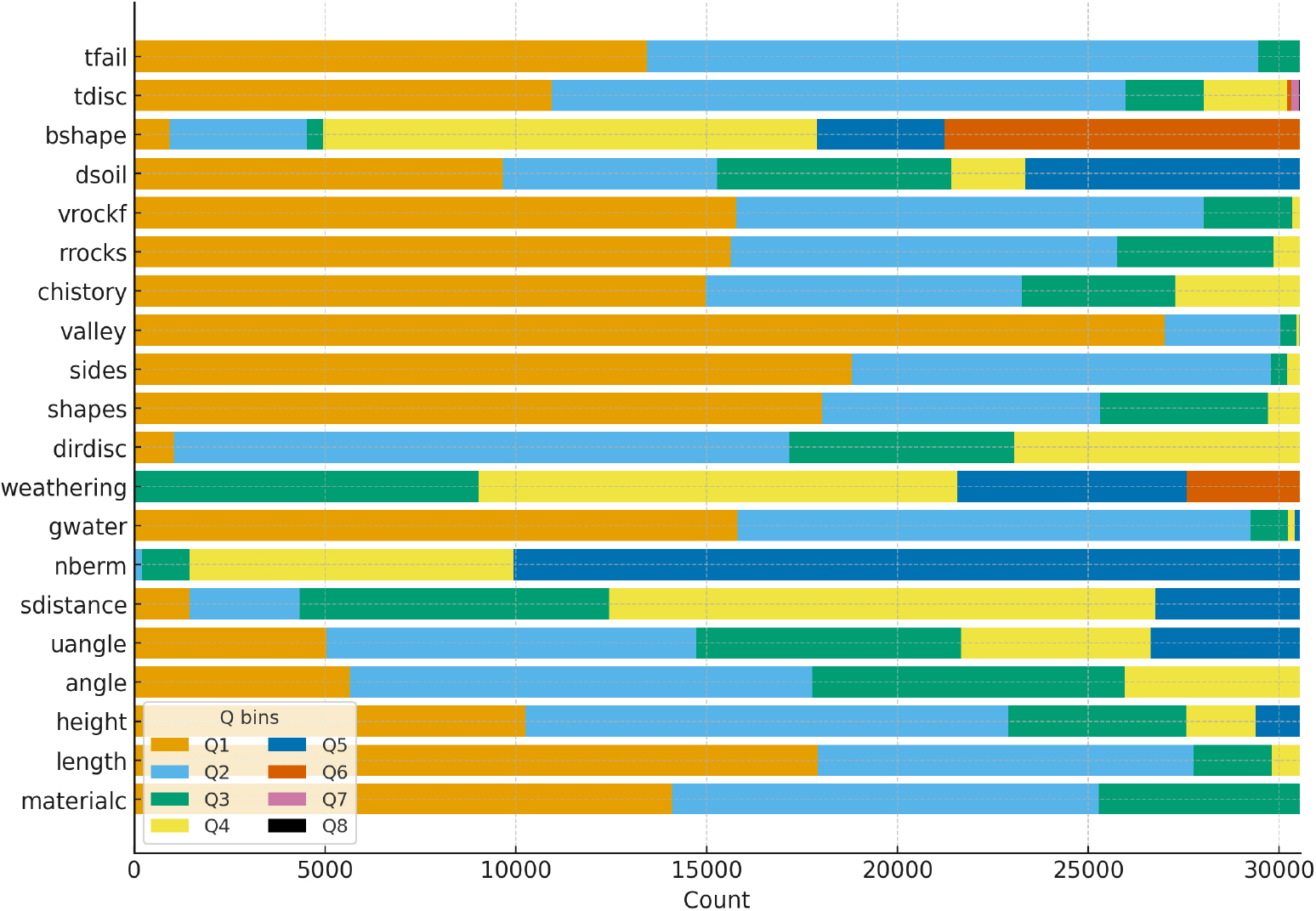
Table 2.
Countermeasure method and their overall proportions
본 데이터는 2006–2024년 동안 현장별 필요 시점에 수집된 비시계열 관측 자료로, 동일 현장의 반복·정기 관측과 표준화된 조사연도 변수가 일관되게 존재하지 않았다. 따라서 본 연구는 시계열/패널 분석을 적용하지 않고, 비시계열 관측자료에 대한 다변량 예측과 변수 기여도 해석에 초점을 두었다.
데이터 전처리
현장 적용성을 높이고 분석의 일관성을 확보하기 위해, 본 연구에서는 연속형 변수를 사전에 정의한 실무기준에 따라 범주형으로 변환하였다. 길이(length)는 100 m 미만, 100–200 m, 200–300 m, 300 m 이상 등 4단계로 구분하였으며, 높이(height)는 10 m 미만, 10–20 m, 20–30 m, 30–40 m, 40 m 이상 등 5단계로 구분하였다. 경사(angle)는 45° 미만, 45–55°, 55–63°, 63° 초과의 4단계로, 상부경사(uangle)는 Reverse, 0–10°, 10–20°, 20–30°, 30° 이상의 5단계로 분류하였다. 이격거리(sdistance)는 11 m 이상, 7–10 m, 4–6 m, 1–3 m, 1 m 미만의 5단계로, 소단개소(nberm)는 11개 이상, 7–10개, 4–6개, 1–3개, 없음 등 5단계로 설정하였다. 계곡부(valley)는 0, 1, 2, 3, 4개 이상 등 5단계로, 토층심도(dsoil)는 0.5 m 미만, 0.5–1.0 m, 1.0–2.0 m, 2.0–3.0 m, 3.0 m 이상 등 5단계로 구간화하였다. 이러한 구간 설정은 비탈면 설계·시공 및 유지관리 지침에서 제시하는 실무 기준과 선행연구의 범주화 방법을 참고하여 이루어졌다(KICT, 2019; Kim and Kim, 2024).
데이터 품질 관리를 위해 오류값을 우선적으로 수정하였다. 예를 들어, ‘졀리’를 ‘절리’로, ‘weT’를 ‘wet’로 정규화하였다. 결측값은 전문가 검토를 거쳐 적정 클래스 값으로 대체하거나, 해당 항목에 “미확인” 범주를 추가하여 처리하였다. 마지막으로, 클래스 분포를 점검한 결과 대책공법(measure)에서 앞 절에서 확인한 바와 같이 ‘현상태 유지’가 가장 높은 비중을 차지하는 편중 현상이 확인되므로, 이는 이후 해석 단계에서 중요한 고려 사항으로 반영하였다.
연구방법론
본 장의 목적은 CSMS 기초조사 데이터를 기반으로 대책공법(measure)을 예측하고, 변수별 기여도 및 변수간 상관성을 해석하기 위한 분석 절차와 적용 알고리즘을 설명한다. 전체 분석은 두 가지 핵심 방법론인 XGBoost 기반 분류 모델과, SHAP 기반 변수 기여도 해석으로 구성된다.
XGBoost는 Gradient Boosting Decision Tree (GBDT)의 확장 알고리즘으로, 다수의 약한 학습기(의사결정나무)를 순차적으로 학습시켜 성능을 향상시키는 앙상블 기법이다. 모델의 전체 목적함수는 식 (1)로, 과적합 억제를 위한 정규화 항은 식 (2)로 나타낸다. 각 단계는 이전 단계의 오차를 보완하는 방식으로 학습하며, 목적함수에는 L1·L2 정규화가 포함된다.
여기서, 은 실제 값 와 예측값 간의 손실을 나타내며, 나타내며, 는 트리 복잡도에 대한 과적합을 막기 위한 규제항이다. 는 트리의 단말 노드이며, 𝛾, 𝜆는 모델 복잡도 제어 파라미터이다.
SHAP은 모델 예측에 대한 변수별 기여도를 정량화하는 방법이며, 기본 가산 분해식은 식 (3)으로 표현한다. 변수 𝑗의 기여도 정의는 식 (4)를 따른다. 이를 통해 트리 기반 비선형 모델의 예측을 “왜 그런 예측이 나왔는가”의 관점에서 해석 가능하게 한다. XGBoost처럼 트리 기반의 비선형 모델은 일반적으로 블랙박스 형태의 예측 결과를 생성하지만, SHAP은 이를 “왜 이런 예측이 나왔는가?” 설명할 수 있도록 해석 가능한 방식으로 구조화한다. SHAP의 식은 식 (3)과 같다.
여기서, 𝛷0는 전체 데이터셋의 평균 예측값, 는 번째 변수의 기여도, 은 전체 특성 개수이며, 아래의 마진 기여를 모든 특성 조합에 대한 평균한 값으로 계산되며, 의 평균 예측값은 식 (4)와 같이 계산된다.
여기서, 는 Feature 부분집합, 는 전체 Feature 집합, 는 집합 를 이용한 모델 예측 기댓값을 의미한다. SHAP 값의 절대값이 클수록 해당 변수의 영향력이 크며, 0에 가까운 경우 영향이 거의 없는 것으로 간주된다.
Goodman-Kruskal’s λ는 변수와 결과 간 연관도를 나타내는 지표로, 분류오차 감소율의 정의는 식 (5)와 같다. λ 값은 0–1범위에서, 클수록 예측자 X가 종속변수 Y 예측에 더 유용한 정보를 제공한다.
여기서, 은 정보를 사용하지 않고 를 예측했을 때의 오차(전체 모드 기준)이며, 는 의 각 범주별 모드를 사용하여 를 예측했을 때의 오차이다.
본 연구는 Python 3.11 환경에서 pandas, numpy, scikit-learn, xgboost, shap 라이브러리를 사용하여 구현되었다. 데이터는 공법별 분포가 유지되도록 무작위 학습용 80%, 테스트용 20%로 분할하였으며, 모든 범주형 변수는 사전 정의된 구간 또는 코드에 따라 정수 매핑하였다. XGBoost의 경우 Table 3과 같이 환경설정을 하였다. n_estimators는 부스팅 반복 횟수(트리 수)로, 값을 늘리면 모형 복잡도가 커져 성능이 향상될 수 있으나 계산 시간과 과적합 위험이 증가하기 때문에 균형을 고려해 150으로 설정하였다. max_depth는 트리의 최대 깊이로, 값이 커질수록 고차 상호작용을 포착할 수 있으나 과적합 위험이 증가하므로 데이터 특성에 맞추어 5로 제한하였다. learning_rate는 각 트리의 기여를 축소하여 점진적으로 학습하도록 하는 계수로, 값을 0.1로 두어 과적합을 억제하는 대신 필요한 트리 수를 보완하였다. subsample과 colsample_bytree는 각각 표본과 특성의 무작위 추출 비율로서 분산을 줄이고 상관 특성이 많은 상황에서 일반화를 돕도록 각각 0.8로 설정하였다. objective는 목적함수로 다중분류용 multi:softprob를 사용하였고, num_class는 대책공법의 클래스 개수에 맞추어 7로 지정하였다. reg_lambda는 규제항으로는 1로 설정하여 가중치를 축소·희소화함으로써 일반화를 향상시켰다. 트리 생성 알고리즘 tree_method는 데이터 규모와 연산 환경을 고려해 hist를 사용하여 학습 속도와 메모리 효율을 확보하였다.
연구 결과
본 절에서는 도출된 결과를 분석하였다. 우선 XGBoost 모델의 혼동 행렬(confusion matrix)로 공법별 예측 특성과 분류 성능을 확인하고, XGBoost, SHAP, Goodman-Kruskal’s λ를 활용하여 변수별 예측 기여도 및 연관도를 비교·해석하였다. 이후 세 기법 간 순위 일관성을 Spearman 상관계수로 검증하고, SHAP 상호작용을 통해 단일 변수를 넘는 결합 요인의 효과를 분석하였다. 마지막으로 상위 10개 핵심 변수를 종합하여 공법 선정 시 고려해야 할 주요 요인을 정리하였다.
Fig. 2는 본 연구에서 구축한 XGBoost 모델의 혼동 행렬 결과를 나타낸다. 가로축은 예측된 공법(predicted), 세로축은 실제 공법(true)을 의미한다. 색의 농도가 진할수록 해당 구간의 표본 수가 많고, 밝을수록 빈도가 높음을 뜻한다. 전체적으로 ‘현상태 유지(status quo, 클래스 0)’와 ‘기타(other, 클래스 6)’에서 일치가 뚜렷하여 높은 분류 정확도를 보였는데, 이는 두 클래스의 표본 수가 상대적으로 많아 학습 과정에서 분기 규칙이 안정적으로 형성된 데에 기인한다. 반면 ‘활동하중경감(1)’, ‘활동억제(2)’, ‘수리제어(5)’와 같은 소수 클래스는 불일치가 다소 관찰되었다. 이는 해당 공법들이 유사한 입력 특성을 공유하여 경계가 모호하기 때문이며, 실제 현장에서도 동일 조건에서 ‘활동 억제’와 ‘수리 제어’가 상호 대체적으로 적용되는 상황을 반영한다. 본 연구는 예측 정확도 상승 자체가 아니라 변수 기여도 및 상호작용 해석에 목적을 두므로, 혼동 행렬은 공법 간 유사성과 차이를 확인하는 자료로 활용하였다.
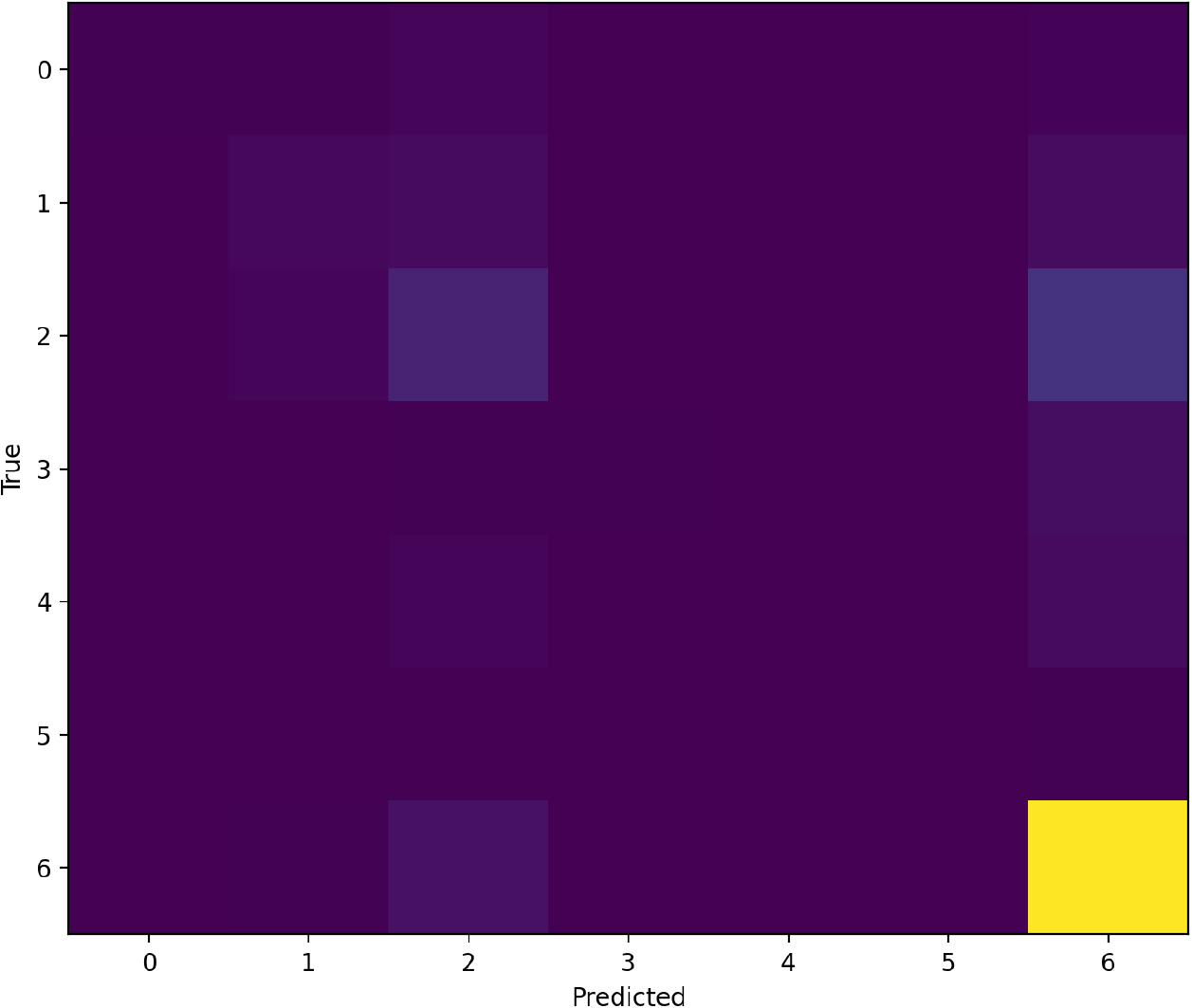
Fig. 3은 변수 예측 기여도 비교 결과로, XGBoost 기반 기여도, SHAP 기반 평균 절대 기여도, Goodman-Kruskal’s λ를 보여준다. XGBoost는 데이터의 분기 규칙을 학습하여 변수 기여도를 산정하므로, 구조·지질·이력 계열 요인—예: tfail, chistory, rrocks—이 상위권을 차지하였다. 이는 과거 붕괴 경험이 있는 비탈면은 재위험이 크다는 현장 지식을 확인할 수 있었다. SHAP 분석은 개별 예측을 변수 단위로 분해하여 기여 방향과 크기를 보여주며, 여기서도 tfail, chistory가 가장 큰 기여를 보였다. 아울러 dsoil, nberm, angle 등 형상·지반 요인의 기여도도 높게 나타났다. 예컨대 토층심도가 깊으면 집중호우 시 약화되기 쉬워 공법 필요성이 커지고, 경사각이 클수록 안정성이 낮아지는 경향이 있다. Goodman-Kruskal’s λ는 변수-공법 간 단변량 명목 연관도를 제공하는 지표다. 본 연구에서 활용한 기초 데이터에서 변수별 λ의 절대값은 전반적으로 낮아, 단일 변수만으로 공법을 구분하기에는 λ(tfail) = 0.0204, λ(chistory) = 0.0176, λ(gwater) = 0.0000, λ(sdistance) = 0.0000 등 설명력이 제한적이었다. 이 결과를 바탕으로 다음 절에서는 먼저 세 기법 간 변수 순위의 일관성을 Spearman 순위상관으로 점검하고, 이어서 SHAP 상호작용을 통해 변수 간 결합 효과를 해석한다.
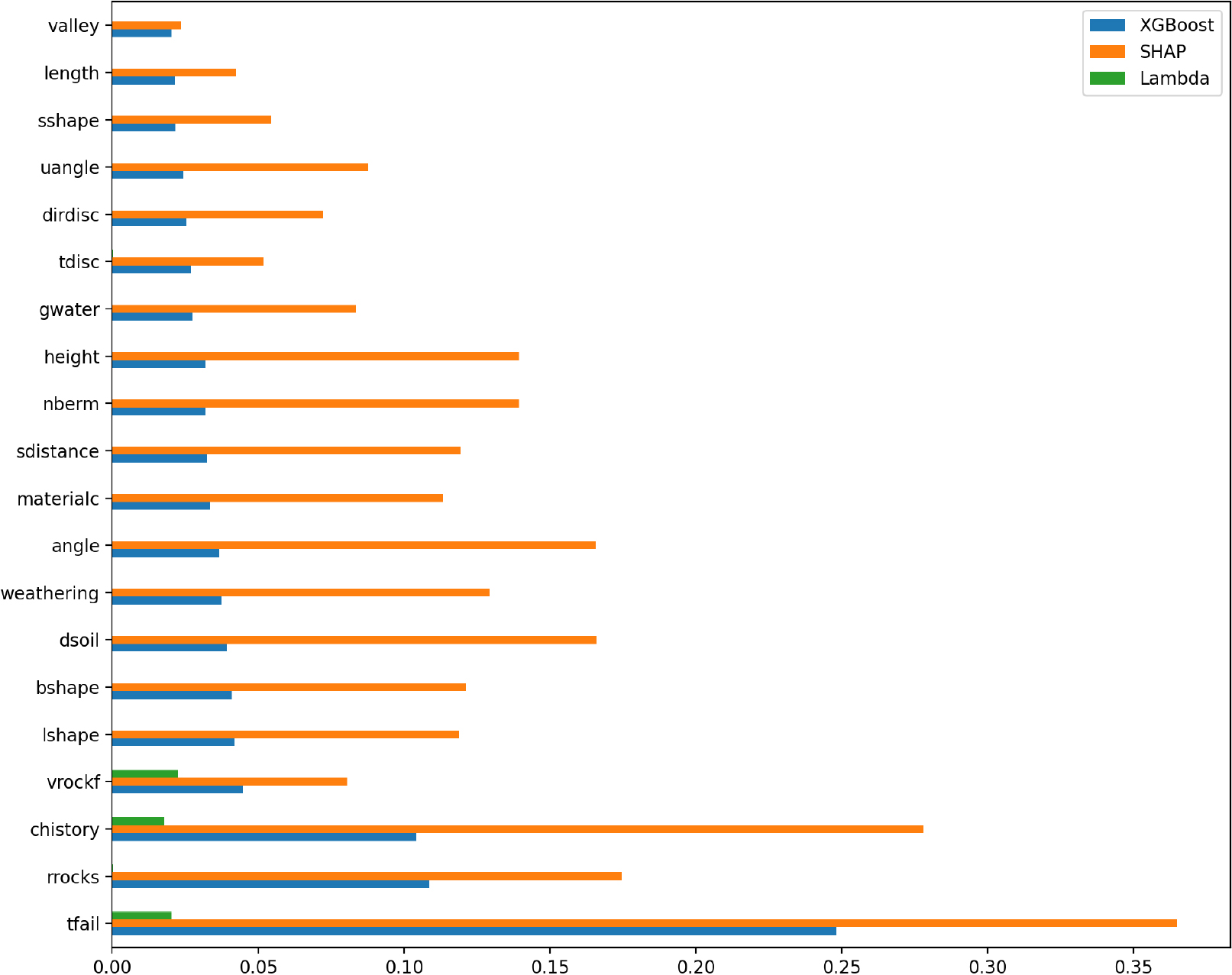
Fig. 4는 세 기법 간 변수 순위를 Spearman 상관계수로 비교한 결과이다. XGBoost-SHAP 간 상관계수(ρ)는 약 0.8로 매우 높아 상위 변수 순위가 크게 일치하였다. 두 지표가 동일한 트리 모형의 분기 규칙에서 나온 정보를 공유하기 때문이다. 반면 λ와의 상관은 약 0.6 수준으로 상대적으로 낮았는데, 이는 λ가 단변량 명목 연관도로 다수의 클래스가 존재하는 경우에, 최빈으로 유지되는 불균형상황이 발생하면 λ가 0에 수렴하기 쉬워 범위가 축소되므로 XGBoost 및 SHAP과의 일치도는 상대적으로 낮아질 수 있기 때문이다. 그럼에도 불구하고 세 기법 모두에서 tfail, chistory, rrocks 등 핵심 변수군이 공통으로 상위권에 나타나, 모델 기반 해석과 통계 기반 연관도가 동일한 정보를 가리킨다는 점을 확인하였다.
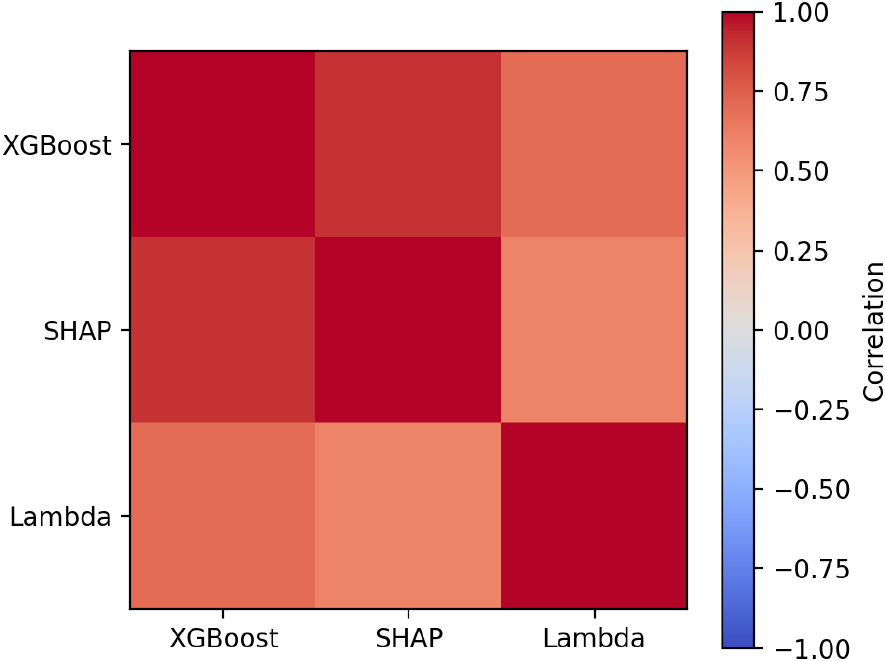
Table 4는 SHAP 기반 상위 10개 상호작용을 요약한다. 가장 큰 상호작용은 tfail-rrocks (≈0.029)로, 붕괴 유형과 뜬돌의 병존이 낙석·활동 대응계열 처방의 필요 신호를 크게 증폭함을 보여준다. tfail-chistory (≈0.026)는 동일한 붕괴 유형이라도 과거 이력이 존재할 때 위험 신호가 강화됨을 시사하며, chistory-rrocks (≈0.024)는 붕괴 이력과 뜬돌의 결합이 재발 및 낙석 위험을 동시 증폭시켜 낙석 방지와 저항계열 보강의 병행 검토 필요성을 뒷받침한다. 나머지 상위 조합들 역시 단일 변수 중요도로는 설명되지 않는 결합효과를 통해 예측 기여를 유의하게 증폭하는 경향을 보인다. 이러한 결과는 단일 변수만으로는 놓치기 쉬운 결합 요인을 드러내며, Goodman-Kruskal’s λ로는 확인할 수 없는 복합 효과를 보완한다는 점에서 실무적 가치가 있다.
Table 4.
SHAP Top 10 combination
앞에서 분석된 결과에 따라 최종적으로 도출된 상위 10개 변수는 tfail, chistory, rrocks, dsoil, vrockf, tdisc, sdistance, valley, bshape, uangle이다. 먼저 위험·이력 범주에서는 tfail과 chistory가 공법 선택에 가장 직접적으로 작용하였다. 구조·지질 범주에서는 rrocks, vrockf, tdisc, dsoil이 비탈면 내부의 취약함을 보여 주어, 보강·표면보호와 같은 처방의 필요도를 높였다. 환경·수리 범주에서는 sdistance와 valley가 인접 조건과 물길의 영향을 반영하여, 배수·방호를 우선 고려해야 함을 보여주었다. 형상 범주에서는 uangle과 bshape가 대표 변수로 확인되었고, 상부 경사가 클수록 불리한 조건이 형성되었다. 종합하면, 과거 경험(위험·이력)-내부 약점(구조·지질)-외부 여건(환경·수리)-기하 상태(형상)가 함께 작동해 공법 선정에 영향을 미치며, 실제 처방에서는 단일 값뿐 아니라 주요 조합(예: tfail-rrocks, tfail-chistory, chistory-rrocks)을 함께 점검하는 접근이 타당하다.
결 론
본 연구는 도로비탈면관리시스템 기초조사 데이터를 활용하여 비탈면 붕괴 요인이 대책공법 선정에 미치는 영향을 정량적으로 분석하였다. 분석 기법으로는 XGBoost를 통한 변수 예측 기여도 산출, SHAP을 활용한 기여도 해석, 그리고 Goodman-Kruskal’s λ를 이용한 변수 및 결과 간 연관성 평가를 병행하였다. 나아가 Spearman 상관분석을 통해 기법 간 일관성을 확인하고, SHAP 상호작용 분석을 통해 변수 간 결합 효과를 추가적으로 검증하였다.
분석 결과, 붕괴 유형(tfail), 붕괴 이력(chistory), 뜬돌(rrocks), 토층심도(dsoil), 풍화도(weathering)와 같은 위험·지질 관련 변수가 공법 선정에 가장 직접적이고 강력한 영향을 미치는 요인으로 확인되었다. 형상·구조 변수(sshape, lshape, angle, uangle, height 등)는 단독 예측력은 상대적으로 낮았으나, 위험·지질 변수와 결합될 경우, 예측 성능에 크게 기여하는 상호작용형 변수로 드러났다. 이는 공법 선정에서 단일 변수의 영향만으로는 충분하지 않으며, 변수 간 상호작용이 핵심적 역할을 한다는 사실을 보여준다. 특히 SHAP 상호작용에서는 tfail-rrocks가 가장 큰 결합효과를 보였고, 이어 tfail-chistory, chistory-rrocks가 높은 상호작용을 보여, 붕괴가 다변량 요인의 복합적 작용임을 실증적으로 확인하였다. 한편 Goodman-Kruskal’s λ 역시 상위 변수군에서 0.00–0.02의 낮은 값을 보여 단변량 연관도의 한계를 시사하였으나, 상위 변수군의 방향성은 유사하여 통계적 접근과 모델 기반 접근이 상호 보완적으로 해석 가능함을 확인하였다. 이는 단일 요인에 의존하지 않고 다변량 상호작용을 고려함으로써 변수 영향도의 신뢰성과 해석 가능성을 높였다는 점에서 의의가 있다. 또한 세 기법에 대한 Spearman 순위상관분석 결과, XGBoost와 SHAP 간 변수 순위는 ρ≈0.8로 높은 일관성을 보였다.
본 연구는 실무적 측면에서 다음과 같은 시사점을 제공한다. 첫째, 전국 단위 CSMS 데이터를 활용하여 공법 선정 요인을 체계적으로 규명함으로써, 현장 경험 의사결정을 데이터 기반 정량적 체계로 전환할 수 있도록 한다. 둘째, 변수 중요도와 상호작용 효과를 동시에 반영함으로써, 직접 영향 변수와 보조적·상호작용 변수의 역할을 구분하여 보다 정교한 관리 전략을 수립할 수 있다. 셋째, 클래스별 성능 분석에서 일부 소수 클래스의 예측력이 낮게 나타났는데, 향후에는 class weight, 비용 민감(cost-sensitive) 학습, SMOTE/ADASYN, 임계값 조정 등 보정 기법을 적용해 분류 신뢰도를 제고할 필요가 있다.
본 연구는 비탈면의 구조·지질·지형적 요인을 중심으로 분석을 수행하였기에, 강우·지진 등 외부 환경 요인이나 시계열적 변동 요인을 직접 반영하지 못하였다. 그러나 이러한 제한은 데이터 자체의 결함이라기보다는 연구 설계의 범위에서 기인한 것으로, 향후 외부 요인과 동적 변화를 포함하는 고도화된 분석을 통해 보완될 수 있다.
향후에는 강우량, 지진, 시계열 이력, 정밀조사 세부 항목, GIS 기반 기하 특성 등 외부 변수를 통합하여 공간-시계열 분석이 가능한 고도화된 예측 모델에 관한 연구를 할 예정이다.
