

서 론
비탈면은 사회기반시설 확보를 위해 조성되며, 자연적으로 형성된 자연비탈면과 인공적으로 만든 인공비탈면으로 나눌 수 있다(Kim et al., 2011; Lee et al., 2019a). 이 비탈면은 불균질한 토양과 암반으로 구성되어 있어 불연속면의 상태와 방향에 민감하며, 기상 변화나 지진 등으로 인해 항상 붕괴 위험에 노출된다(Park et al., 2006). 따라서 비탈면의 안정성을 평가하고 모니터링을 통해 붕괴 위험 요인을 파악하고 대책을 수립하며, 지속적인 유지보수가 필요하다(MLTMA, 2011).
도로비탈면관리시스템(cut slope management system, CSMS)은 국토교통부의 위탁을 받아 운영되며, 한국건설기술연구원과 국토안전관리원이 이를 통해 지역별로 도로비탈면 관리를 수행한다(KICT, 2019). CSMS의 주요 목적은 전국 도로비탈면의 현황을 파악하고 위험 등급을 산정하여 연차별 유지대책을 마련함으로써 비탈면 붕괴를 사전에 방지하고 도로 이용자의 안전을 보장하는 것이다(KICT, 2019). CSMS는 국도 주변의 모든 깎기 비탈면에 대한 데이터베이스를 구축하고 이를 매년 갱신하며, 갱신된 데이터를 바탕으로 전문가들이 위험이 높은 비탈면에 대해 정밀 조사를 수행하고 적절한 대책을 제시한다. 이러한 의사결정 과정은 투자 우선순위를 결정하고 국가 예산의 투명하고 효율적인 집행을 지원한다. 최근에는 스마트폰과 웹을 활용해 현장에서 즉시 데이터에 접근할 수 있는 시스템 구축 연구가 진행되며, 이는 더 빠른 데이터 수집을 가능하게 한다. 결과적으로, 수집된 데이터를 활용한 연구는 매우 중요하게 다뤄진다.
CSMS의 대표적인 활용 방안 중 하나는 대책공법의 수립이다. 최신 장비와 기술을 이용한 예측 및 분석 연구가 진행되고 있으나, 붕괴 요인 간의 관계 파악 부족과 단순 예측에 그치는 연구가 많아 여전히 부실한 상황이다. 요인 간의 상관 분석은 두 변수 간의 선형적 관계를 분석하여 연관 정도를 확인하는 방법이다. 또한, 인공지능을 활용한 예측 모델을 통해 객관적인 정보에 기반하여 대책공법의 종류를 예측할 수 있으며, 이를 통해 전문가의 의사결정 과정에서 인간 오차를 줄이는 데 기여할 수 있다.
이를 위해 본 연구는 붕괴 요인 간의 상관 분석과 인공지능을 활용한 대책공법 예측을 통해 의미 있는 결과를 도출한다. 대표적인 상관분석 방법인 Cramér’s V 상관계수를 활용하여 CSMS의 기초 조사 데이터 중 비탈면 붕괴를 유발하는 주요 요인들(비탈면 종류, 주변 지형, 지하수, 풍화도, 불연속면 방향성, 비탈면 형상, 측면 현상, 붕괴 이력, 뜬돌, 낙석, 암반 형태, 불연속면) 간의 상관 관계를 살펴본다. 또한, Random Forest, XGBoost, LightGBM, CatBoost의 앙상블 기반 알고리즘과 DNN(deep neural network), TabNet의 딥러닝 기반 알고리즘을 활용하여 대책공법인 현상태 유지, 활동 하중 경감 공법, 활동 억제 공법, 낙석 제어 공법, 표면 보호 공법, 수리 제어 공법, 기타 공법의 총 7가지 공법에 대한 예측 모델을 설계한다. Cramér’s V 상관계수는 범주형 변수의 상관관계를 정량적으로 평가하기 적합한 지표로, 차원과 관계없이 강도를 측정한다. 앙상블 기반 알고리즘은 개별 모델들이 약점을 상호 보완하며, 과적합을 줄인다. 특히 다양한 의사결정 트리를 결합하여 예측의 분산을 줄이고 일반화 성능을 개선하기 때문에, 범주형 데이터나 소규모 데이터셋(data set)에서도 탁월한 성능을 발휘한다. 또한 딥러닝 기반 알고리즘은 복잡한 데이터 패턴을 학습하는 데 뛰어나며, 대규모 데이터셋에서도 우수한 성능을 보여준다. 본 연구에서는 다양한 데이터로 이루어진 CSMS 기초조사 데이터를 활용하기 때문에 일관된 해석을 제공하는 Cramér’s V 상관계수와 안정적인 예측 성능을 발휘하는 앙상블 기반 알고리즘과 딥러닝 기반 알고리즘을 활용하였다. 그 결과, 비탈면 붕괴 요인 중 비탈면 종류와 풍화도, 붕괴 이력과 붕괴 유형, 비탈면 종류와 암반 형태가 가장 큰 관계를 가진 것으로 확인되며, 예측에 대해서도 앙상블 기반 알고리즘이 전반적으로 높은 예측 성능을 보였다. 이를 통해 고품질의 데이터베이스를 구축하고, 유사 비탈면 분류와 함께 더 정밀한 대책공법을 제공할 수 있으며, CSMS의 활용도를 높일 수 있을 것으로 기대된다.
본 논문은 다음과 같은 구성으로 진행된다. CSMS 기초 조사 비탈면 데이터를 분석하고, 비탈면 붕괴 요인을 Cramer’s V 상관계수를 활용하여 상관 분석한다. 인공지능을 활용해 예측 모델을 설계하고, 최종적으로 연구의 결론과 의의를 논의한다.
CSMS 기초조사 데이터
데이터 구성
비탈면 붕괴 예측을 위한 상관 분석 및 예측 모델 개발에는 CSMS의 기초조사 데이터에 대한 이해가 필요하다. CSMS 데이터는 기초조사와 정밀조사 데이터로 나뉜다. 기초조사 데이터는 국토관리사무소(또는 지자체)로부터 제공받은 전국 국도변의 모든 비탈면에 대한 기초적인 행정구역, 구간, 연장 등의 속성 자료를 포함한다. 기초조사는 전국 국도변에 위치한 모든 깎기 비탈면의 기본적인 속성 항목(관리 및 위치정보, 일반 현황, 비탈면 특성, 조사자 소견, 사진 등)을 파악하고 관련 자료를 취득하는 전수조사를 의미한다(KICT, 2019). 이 자료는 체계적이고 과학적인 비탈면 관리를 위해 각 비탈면에 고유 코드를 부여하여 데이터베이스화되며, 조사 우선순위를 결정하는 중요한 자료로 활용된다. 2001년에 도로관리기관이 직접 기초조사를 수행하였으나, 정확한 위치나 수량의 기재 부족, 데이터의 결손, 표준화 문제 등 자료의 품질이 좋지 않았다. 이 문제를 극복하기 위하여 2006년부터 2010년 기간 중 연구기관들에 의해 일반국도 깎기비탈면에 대한 전체적인 기초조사가 다시 수행되었다. 이 때에는 비탈면에 대한 코드번호 부여 약속이 결정되었을 뿐만 아니라 비탈면 전문가에 의해 조사되는 점을 감안하여 보다 자세한 지반, 지질, 수리 정보들이 기록되었다.
본 연구에서 사용된 CSMS 데이터는 2006년부터 2019년까지 수집된 30,719개 비탈면에 대한 기초조사 데이터로, Table 1에 나타난 바와 같이 비탈면 기본 정보(코드, 위치 등), 길이, 최대 높이, 경사, 상부 경사, 이격거리, 소단 개소수 등의 연속형 정보와 비탈면 종류, 주변 지형, 지하수, 풍화도, 불연속면 방향성 등의 비탈면 특성, 위험도 및 대책공법과 같은 범주형 변수로 구성된다.
Table 1.
Composition of CSMS basic investigation data
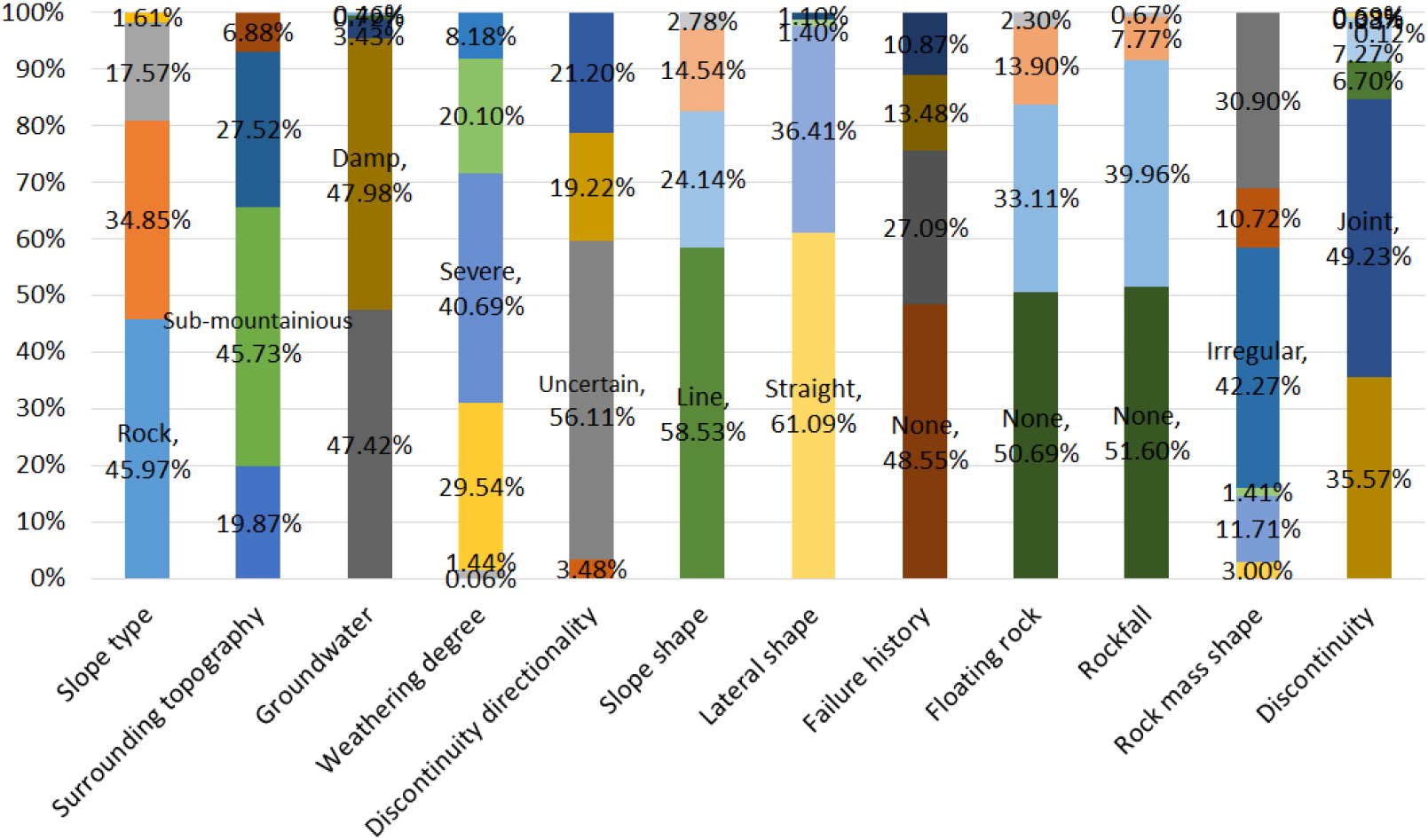
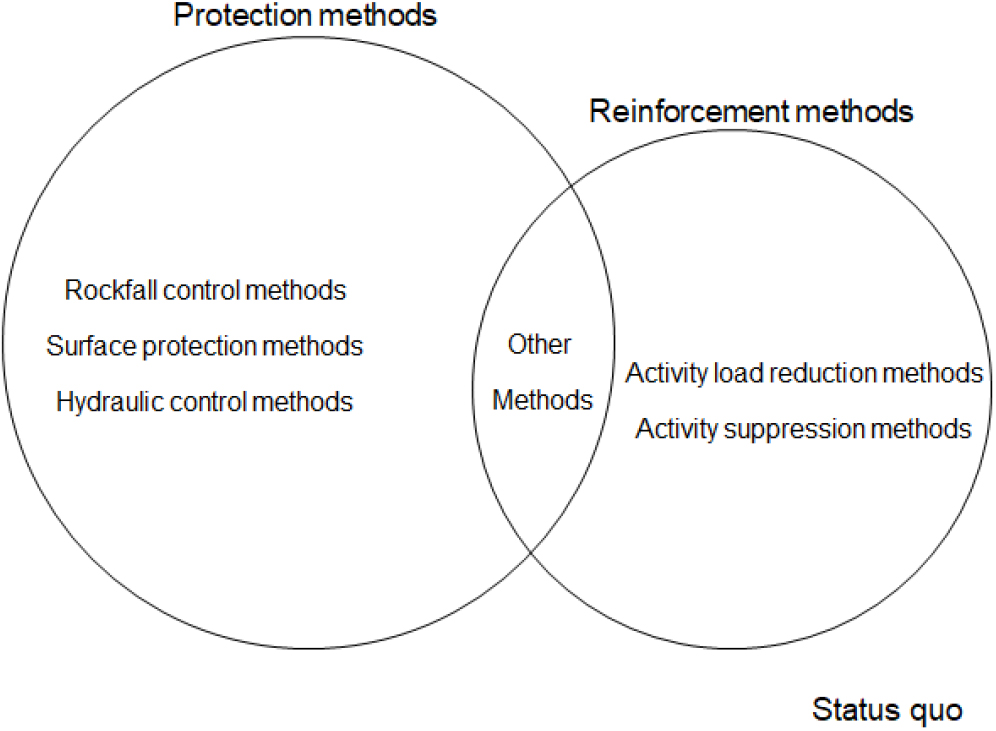
이 중 본 연구에 활용된 범주형 변수에 대해서 Fig. 1로 나타내었다. 지하수를 제외하고 대부분의 세부 요인들의 값이 균등하지 않으며, 이는 각 요인마다 비중이 가장 두드러지게 나타나는 주요 클래스가 존재함을 보여준다. 비탈면 종류는 ‘암반’, 주변 지형은 ‘준산악’, 지하수는 ‘damp’, 풍화도는 ‘심한풍화’, 불연속면 방향성은 ‘확인불가’, 비탈면 형상은 ‘직선형’, 측면 형상은 ‘직선형’, 붕괴 이력은 ‘무’, 뜬돌은 ‘무’, 낙석은 ‘무’로, 각각의 개별 요인이 약 50%를 차지한다. 이러한 요인 외에 비탈면 붕괴 대책공법은 ‘현상태유지’를 포함하여 ‘보호공법’과 ‘보강공법’, 그리고 ‘기타공법’으로 나누어진다. 보호공법은 깎기비탈면이 자체적으로 안정된 상태에서 외부의 비탈면 붕괴 발생 요인을 차단하는 방법이다. 보강공법은 비탈면 자체가 안정성을 확보하지 못한 상태에서 강제적인 조치를 통해 비탈면의 안정성을 확보하는 방법이다. Fig. 2에서처럼 보호공법은 ‘낙석 제어 공법’, ‘표면 보호 공법’, ‘수리 제어 공법’으로 나누어지며, 보강공법은 다시 ‘활동 하중 경감 공법’과 ‘활동 억제 공법’으로 구성된다.
전처리
CSMS 기초조사 데이터는 빅데이터에 비해 방대한 양은 아니지만, 조사자가 기록한 데이터이므로 오기입이 존재할 수 있다. 예를 들어, ‘절리’가 ‘졀리’로, ‘wet’이 ‘weT’으로 잘못 입력된 경우가 있었다. 엑셀 데이터 전체를 살펴 일일이 오기입을 수정하였다. 또한, 수치 데이터 중 Null 값의 경우에는 전문가의 검토를 통해 데이터를 삽입할 수 있었다. 데이터는 범주형 변수를 포함하고 있기 때문에, 이를 수치로 치환하는 과정이 필수적이다. 예를 들어, ‘주변 지형’ 항목은 ‘구릉’, ‘산악’, ‘준산악’, ‘평지’와 같은 네 개의 클래스를 가지고 있으며, 이는 각각 ‘0’, ‘1’, ‘2’, ‘3’과 같이 임의의 숫자로 치환할 수 있다. 다른 범주형 데이터들도 각 클래스 수만큼 0으로부터 ‘1, 2, 3, ...’과 같은 양의 정수로 치환해야 하며, 모든 데이터를 치환하였다. 또한, 데이터의 클래스 불균형 문제를 해결하기 위해 오버샘플링과 언더샘플링 기법을 적용하여 소수 클래스의 데이터를 증가시키고 다수 클래스의 데이터를 줄이는 작업을 수행하였다. 이를 통해 불균형한 클래스 분포를 개선하여 모델 학습의 성능을 높였다. 더불어, 학습 시 클래스 간 불균형을 보완하기 위해 파이썬의 클래스 가중치(class weight) 기법을 활용하였으며, ‘weight="balanced"’ 설정을 통해 각 클래스별 샘플 수에 비례하여 가중치를 자동으로 계산하였다. 이를 통해 소수 클래스의 손실 값을 증가시켜 모델 학습 시 균형 잡힌 성능을 유도하고 과적합을 방지하고자 하였다.
상관분석
Cramer’s V 상관 분석
본 연구에서는 Cramér’s V 상관계수(Akoglu, 2018)를 활용하여 CSMS 기초조사 데이터에 기록된 붕괴 요인 간의 상관 분석을 실시하였다. Cramér’s V는 두 범주형 변수 간의 연관성을 측정하는 통계량으로, Pearson의 카이제곱 통계량을 사용하여 계산된다. CSMS 기초조사 데이터에서 비탈면 붕괴의 요인 중 범주형 데이터로는 비탈면 종류(암반, 자연, 토사, 혼합), 주변 지형(산악, 준산악, 구릉, 평지), 지하수(Completely dry, damp, dripping, flowing, wet), 풍화도(보통풍화, 심한풍화, 약간풍화, 심한풍화, 풍화잔류토), 불연속면 방향성(불가, 일치, 평행, 확인불가, 후방), 비탈면 형상(요형, 직선형, 철형, 파형), 측면 형상(돌출형, 요출형, 직선형, 탈락형), 붕괴 이력(낙석, 무, 유(미영향), 유(영향)), 뜬돌(대, 중, 소, 무), 낙석(대, 중, 소, 무), 암반 형태(tabular, irregular, crushed, blocky, columnar, massive), 불연속면(엽리, 층리, 절리, 파쇄대, 균열, 단층, 암맥, 엽리, 전단대, 무) 등이 있다. 이들 2개 이상의 범주로 나눈 통계자료의 상관관계를 구하기 위해 활용하는 Cramér’s V 상관계수 식은 아래의 식 (1), (2)와 같다.
여기서, 은 총 개수, 는 데이터를 구성하는 행의 수 또는 열의 수 중 작은 값이다. 은 카이제곱 통계량으로 요인의 값이 존재하는 관찰 빈도() 기대 빈도()를 사용하여 계산한다. 기대빈도 는 각 셀의 행 합계와 열 합계를 총 관측 수로 나눈 값이다. Fig. 3은 Cramér’s V를 통한 상관관계 분석의 결과를 나타낸 그래프이며, 이중 가장 높거나 낮은 상관관계 값과 요인에 대하여 Table 2로 나타내었다. 0에서 1 사이의 값을 가지며, 값이 클수록 두 변수 간의 연관성이 강함을 의미한다.
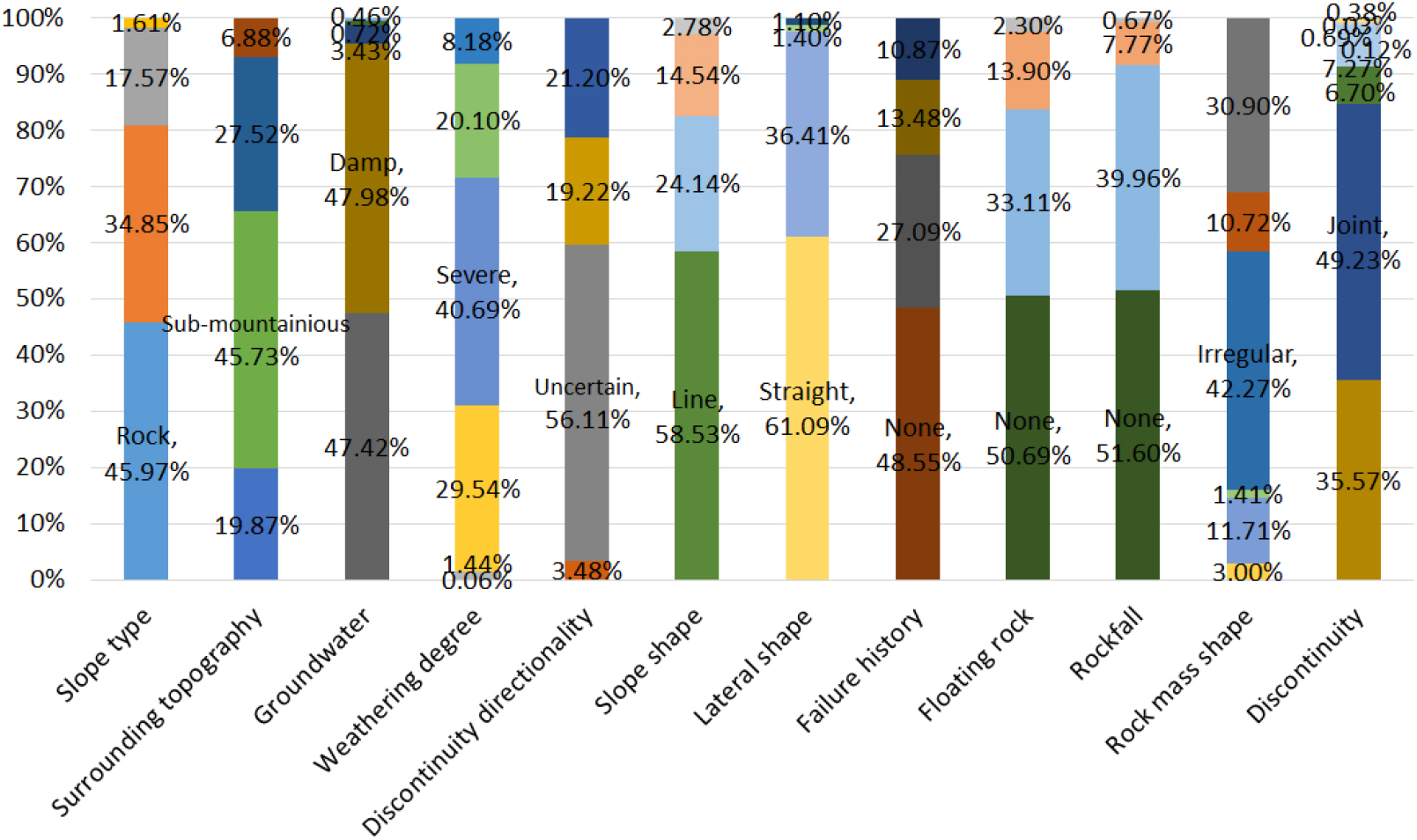
Table 2.
Correlation analysis results using Cramér’s V for key factors of data acquired through CSMS basic investigation
비탈면 종류는 풍화도와 높은 상관관계를 가지며, 지하수와는 가장 낮은 상관관계를 보인다. 주변 지형은 불연속면 방향성과 가장 높은 상관관계를 가지며, 지하수와는 낮은 상관관계를 보인다. 지하수는 붕괴 이력 및 낙석과 관련이 있으며, 풍화도는 비탈면 종류와 높은 상관관계를, 비탈면 형상과는 낮은 상관관계를 가진다. 불연속면 방향성은 낙석과 높은 상관관계를 가지며, 비탈면 형상과는 낮은 상관관계를 보인다. 비탈면 형상은 뜬돌 및 풍화도와 각각 높은 상관관계와 낮은 상관관계를 보인다. 측면 형상은 비탈면 형상 및 주변 지형과 관계를 가지며, 붕괴 이력은 비탈면 형상과 지하수와 관련이 있다. 뜬돌은 비탈면 형상 및 지하수와 관련이 있으며, 낙석은 불연속면 방향성과 지하수와 관계를 가진다. 비탈면 붕괴 요인 중, 특히 비탈면 형상은 다른 요인(측면 형상, 붕괴 이력, 뜬돌, 불연속면)과 전반적으로 높은 상관관계를 가지며, 뜬돌과는 상관계수 0.887464로 가장 높은 연관성을 보인다. 이는 비탈면 형상과 뜬돌이 서로 큰 영향을 주고받는다는 것을 의미한다. 반면, 지하수는 비탈면 종류, 주변 지형, 붕괴 이력, 뜬돌, 낙석, 암반 형태, 불연속면과 가장 낮은 상관관계를 가지며, 특히 낙석과는 상관계수 0.05854로 가장 낮은 관련성을 보인다. 이는 지하수가 낙석에 큰 영향을 미치지 않는다는 것을 의미한다. 결과적으로, 비탈면 형상은 비탈면 붕괴의 주요 원인 중 하나로 다른 요인들과 높은 상관관계를 가지는 핵심 요소로 나타난다. 지하수도 중요한 요인이지만, 계절 및 기후 요인이 반영되지 않아 다른 요인들과의 상관성이 상대적으로 낮게 나타난다.
Cramér’s V 상관분석 결과를 대책공법 예측과 연관지어 보면, 비탈면 붕괴와 관련된 주요 요인들 간의 높은 상관관계는 적절한 대책공법을 예측하는 데 중요한 참고자료로 활용될 수 있다. 예를 들어, 비탈면 형상이 뜬돌과 높은 상관관계를 보인다는 사실은, 뜬돌의 특성과 비탈면 형상이 특정 대책공법 선택에 중요한 기준이 될 수 있음을 시사한다. 이는 비탈면 형상과 뜬돌이 밀접하게 연결된 지점에서는 더 효과적인 공법이 필요할 가능성을 보여주며, 예측 모델이 이를 반영할 때 보다 정확한 대책공법 추천이 가능할 것이다. 또한, 지하수와 낙석 간 상관관계가 매우 낮게 나타난 것은 이들 요인이 서로 독립적이라는 점을 강조하며, 지하수가 포함된 지형에서는 낙석 방지 대책공법의 필요성이 상대적으로 낮을 수 있음을 의미한다. 이는 예측 모델이 대책공법을 제안할 때 각 요인들의 상관관계를 기반으로 맞춤형 공법을 추천하는 데 중요한 역할을 할 수 있음을 나타낸다.
따라서, 비탈면 형상, 뜬돌, 낙석, 불연속면 방향성 등의 상관관계가 높은 요인들은 특정 대책공법의 선택에 중요한 영향을 미칠 수 있다. 반면, 주변지형, 지하수 등의 상관관계가 낮은 요인들은 해당 공법 적용에 있어 상대적으로 덜 중요한 요소로 간주될 수 있다. 이러한 상관분석은 대책공법 예측 모델이 각 요인별 상관성을 적절히 반영하여, 보다 최적화된 공법을 제안할 수 있도록 돕는 중요한 기초 데이터가 될 수 있다.
대책공법 예측 모델
활용 예측 모델
CSMS 기초조사 데이터는 각 현장에 대해 범주형 붕괴 요인과 이에 대한 대책공법으로 구성되어 있다. 본 연구에서는 이러한 데이터를 활용하여 현장에 적합한 대책공법을 예측하는 모델을 개발하고자 한다. 특히, 범주형 붕괴 요인 데이터를 바탕으로 현 상태 유지, 활동 하중 경감, 활동 억제, 낙석 제어, 표면 보호, 수리 제어, 기타 공법 등 다양한 대책공법을 예측하는 모델을 설계하였다. 제안된 예측 모델의 데이터 처리 과정은 Fig. 4에 나타나 있으며, 주요 입력 변수로는 비탈면 종류, 주변 지형, 지하수 상태, 풍화도, 불연속면의 방향성, 비탈면 및 측면 형상, 붕괴 이력, 뜬돌, 낙석, 불연속면 등이 사용된다. 이 입력 데이터를 기반으로 대책공법을 라벨링하여, 트레이닝과 테스트 데이터셋으로 8 : 2 비율로 나누어 모델을 학습시킨다. Table 3은 이 과정에서 활용되는 대책공법의 라벨링 값과 전체 데이터에서 차지하는 비중이다. 이후, 범주형 데이터에서 활용하는 Random Forest(Breiman, 2001), XGBoost(Lee et al., 2019b), LightGBM(Ke et al., 2017), CatBoost(Prokhorenkova et al., 2018)와 같은 앙상블 기반 알고리즘과 DNN(Mittal, 2020), TabNet(Arik and Pfister, 2021)과 같은 딥러닝 기반의 알고리즘을 활용하여 예측 모델을 구축하고, 테스트 데이터를 활용해 예측 성능을 평가한다.
Random Forest는 여러 개의 의사결정 트리를 앙상블하여 예측 성능을 높이는 모델로, 각각의 트리가 독립적으로 학습함으로써 과적합을 줄이고 대규모 데이터에서 우수한 성능을 발휘한다. XGBoost는 여러 개의 의사결정 트리를 결합하여 보다 정교한 트리를 생성하고, 최적화 과정을 통해 과적합 문제를 해결하며, 병렬 연산을 통해 학습 속도를 개선한 알고리즘이다. LightGBM은 대규모 데이터셋을 효율적으로 처리할 수 있도록 설계된 Gradient Boosting 모델로, leaf 중심 트리 분할 방식을 사용하여 학습 속도와 메모리 효율성을 극대화한다. CatBoost는 대칭적인 트리 구조를 사용하여 예측 시간을 단축시키며, 범주형 데이터를 효율적으로 처리하는 데 강점을 지닌 앙상블 모델이다. DNN은 다층의 인공신경망을 통해 데이터를 학습하는 모델로, 입력 계층, 은닉 계층, 출력 계층으로 구성되며, 각 계층에서 비선형 변환을 수행하여 복잡한 패턴을 학습하고, 이를 통해 예측 성능을 향상시킨다. TabNet은 트랜스포머의 주의 메커니즘을 활용하여 표형 데이터를 효율적으로 처리하는 딥러닝 기반 모델로, 중요한 특성을 자동으로 선택하여 모델 해석 가능성을 높이고 예측 성능을 향상시키며, 각 데이터 포인트에 대해 적응형으로 학습하여, 연속형과 범주형 데이터를 모두 효과적으로 처리할 수 있으며, 효율적인 학습과 해석 가능성을 동시에 제공하는 것이 특징이다.
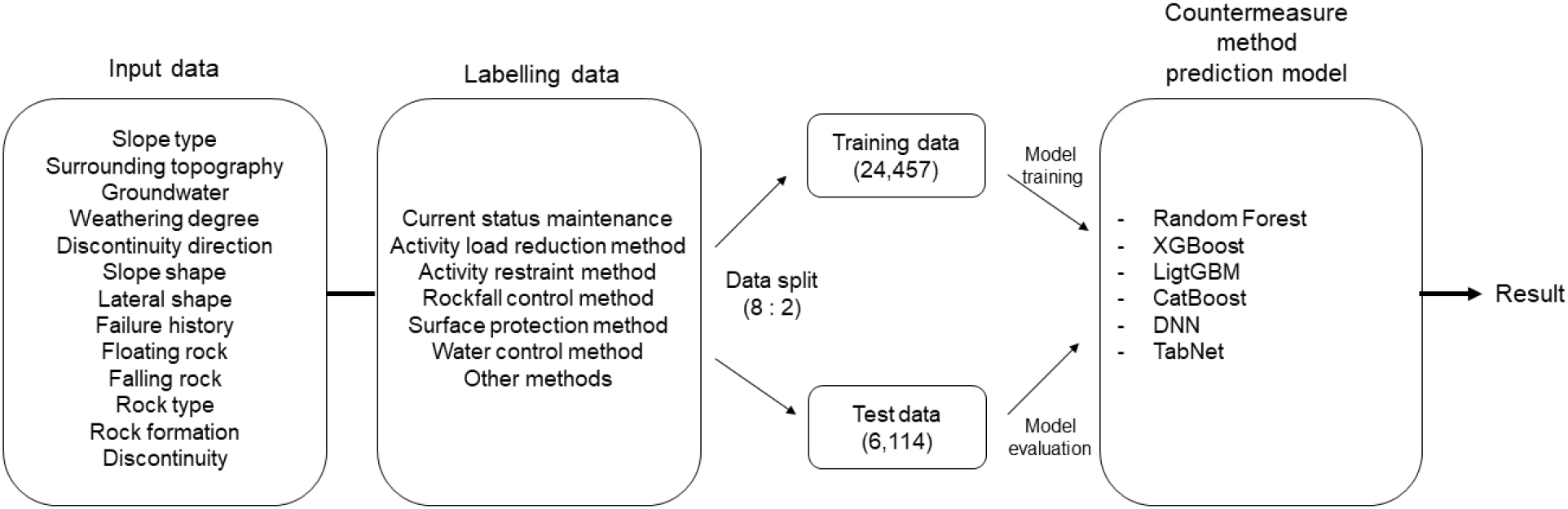
Table 3.
Labeling values of countermeasure method and their overall proportions
실험 최적화
인공지능 알고리즘을 적용한 예측 모델 실험을 위해, 각 모델의 하이퍼파라미터 최적화는 모두 Random Search를 활용한다. Random Search는 파라미터의 범위를 설정한 후, 파라미터의 설정 지점부터 샘플링을 통해 최적의 파라미터 값을 선정하는 방식이다. 각각의 매개변수 설정 시 균일 분포로 샘플링하여 파라미터 결과가 개선되는 경우에만 이전 파라미터 값을 갱신하는 모델이다. 이러한 Random Search를 통해 Random Forest, XGBoost, LightGBM, CatBoost, DNN, TabNet의 파라미터를 최적화하였으며, 각 모델에 대한 최적화 값은 Table 4로 나타난다.
Random Forest는 각각의 의사결정 나무의 최대 깊이를 설정하는 max_depth, 총 의사결정 나무 개수를 설정하는 n_estimators, 나무의 내부 노드 분할에 필요한 최소 샘플 수를 지정하는 min_samples_split, 노드에 개별 잎의 최소 샘플 수를 지정하는 min_samples_leaf를 이용한다. XGBoost는 max_depth, n_estimators, L2 정규화 reg_lambda, L1 정규화 reg_alpha 네 가지 파라미터를 사용한다. LightGBM은 개별 트리가 가질 수 있는 최대 leaf의 개수인 num_leaves와 n_estimators, max_depath, 학습률을 설정하는 learning_rate를 주요 파라미터로 활용한다. CatBoost는 feature에 대한 분할 개수인 border_count, 의사결정 트리의 깊이를 설정하는 depth, 트리의 개수를 설정하는 iterations, 학습률인 learning_rate, 그리고 L2 정규화 항인 l2_leaf_reg를 주요 파라미터로 사용한다. DNN은 각 은닉층에 있는 뉴런의 개수인 n_neurons, 은닉층의 개수인 n_hidden, L2 정규화 값인 l2_reg, 한 번에 가지고 오는 크기를 나타내는 batch_size, 전체 딥러닝 횟수인 epoch, 은닉층의 개수와 각 층의 뉴런 수를 설정하는 layer_dense, 학습률을 설정하는 learning_rate를 이용하여 모델의 파라미터 최적화를 진행한다. TabNet은 cat_emb_dim은 범주형 변수의 임베딩 벡터의 크기, gamma은 특정 규제에 대한 가중치, n_a은 attention 유닛의 수, n_d은 시계열 정보 추출을 위한 채널 수, n_steps 시계열 처리 반복 횟수를 주요 파라미터로 활용한다.
Table 4.
Each algorithms’s hyperparameter
분석 결과
CSMS 기초조사 데이터의 비탈면 붕괴 요인인 비탈면종류, 주변지형, 지하수, 풍화도, 불연속면방향성, 비탈면형상, 측면형상, 붕괴이력, 뜬돌, 낙석, 불연속면의 범주형 변수를 활용하여 Random Forest, XGBoost, LightGBM, CatBoost, DNN, TabNet 여섯 가지 모델을 통해 현상태유지, 활동하중경감공법, 활동억제공법, 낙석제어공법, 표면보호공법, 수리제어공법, 기타공법의 대책공법을 예측하고 평가지표인 Accuracy, Precision, Recall, F1 Score를 통해 모델을 평가하였다. 또한 추가적으로 가장 성능이 좋은 LightGBM과 CatBoost 앙상블 기반 모델을 Voting(Saqlain et al., 2019)을 통해 결합하여 결과를 도출하였다. Accuracy는 정확도로서, 바르게 예측된 데이터의 수를 전체 데이터의 수로 나눈 값이다. Precision은 정밀도로서, 모델이 True로 예측한 데이터 중 실제로 True인 데이터의 수를 의미한다. Recall은 재현율로서, 실제로 True인 데이터를 모델이 True라고 인식한 데이터의 수를 의미한다. F1 Score는 Precision과 Recall의 조화평균이다.
Fig. 5는 평가 지표에 따른 각각의 알고리즘의 예측 결과 값이다. Random Forest, XGBoost, LightGBM, CatBoost는 네 가지 앙상블 기반 알고리즘의 Accuracy, Precision, Recall, F1 score 값은 84.57/85.21/84.57/84.75, 85.45/84.86/85.45/85.09, 84.26/85.03/84.26/84.54, 85.17/85.02.85.17/85.07의 수치를 보였다. 그리고 LightGBM과 CatBoost를 조합한 앙상블 알고리즘은 85.6/85.16/85.6/85.32의 값으로 다른 단독 앙상블 기반 알고리즘에 비해 높은 수치를 보였다. 또한 딥러닝 기반 알고리즘인 DNN과 TabNet은 각각 80.02/84.55/80.62/81.31와 83.07/84.13/83.07/83.42값을 보였다. 대체적으로 앙상블 기반 알고리즘들이 딥러닝 기반 알고리즘들보다 높은 성능을 보였으며, 이는 범주형 데이터의 특성상 결정트리 기반의 앙상블 기반 알고리즘이 범주형 데이터의 구분을 직관적으로 처리하기 때문에 관계를 파악하기 유리하며, 앙상블 기반 알고리즘은 각각의 개별 모델이 서로 다른 데이터를 학습하기 때문에 과적합을 방지하여 더 나은 성능을 보였다. 또한 아주 많은 양의 데이터가 아니기 때문에 딥러닝 기반의 알고리즘들이 상대적으로 성능이 좋지 않았을 것으로 보인다.
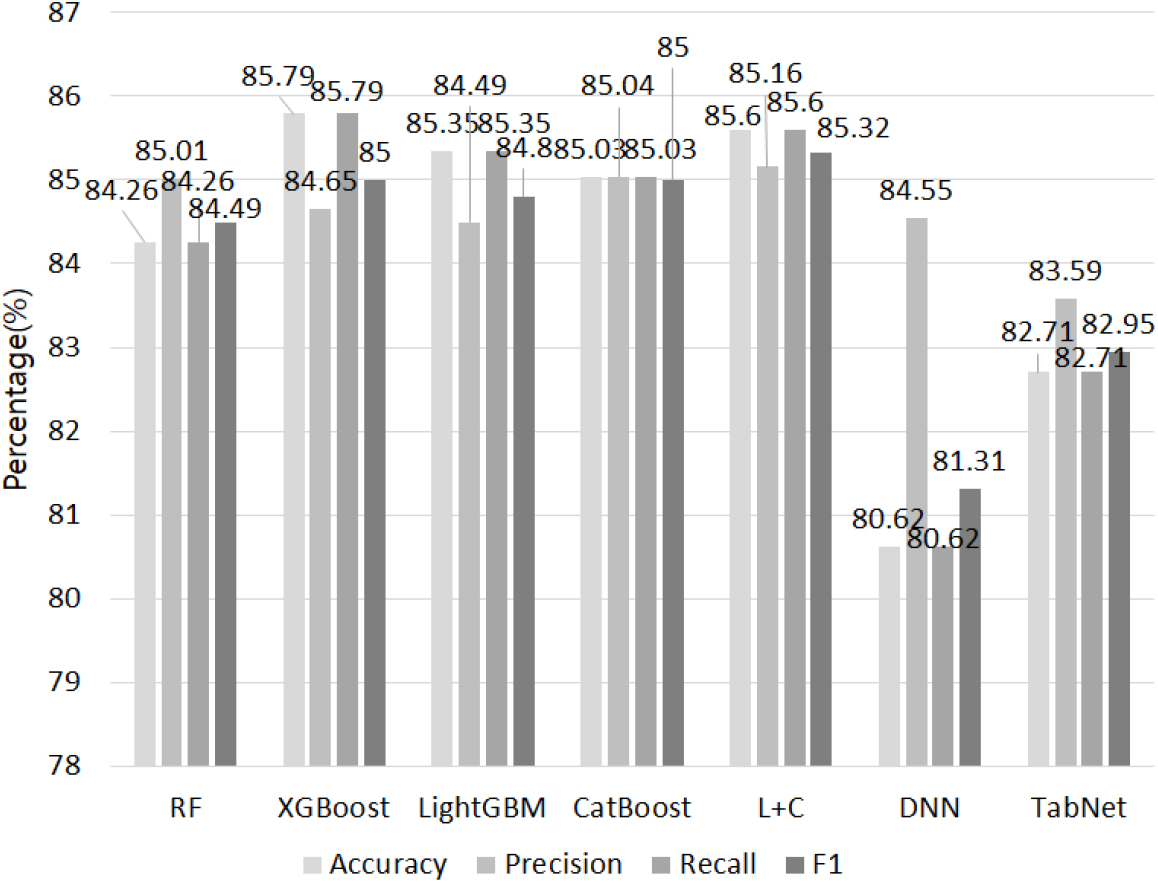
Fig. 6은 각 알고리즘의 Accuracy를 실제 값과 예측 값의 비교로 나타낸 Confusion Matrix를 시각화한 결과이다. 가로 축은 실제 값을, 세로 축은 예측 값을 나타내며, 행렬 내의 값들은 실제값과 예측값의 일치 또는 불일치를 수치적으로 보여준다. 행렬의 대각선 값은 모델이 정확히 분류한 데이터의 개수를 나타내며, 높은 값을 가질수록 해당 클래스에서의 예측 정확도가 높음을 의미한다. 반대로 대각선 외부의 값은 잘못 분류된 데이터의 개수를 나타내며, 이 값이 낮을수록 해당 클래스에서의 모델 성능이 우수함을 보여준다. 오른쪽의 컬러 스케일(범위: 0~4,000)은 각 셀의 값을 시각적으로 표현하며, 값이 클수록 셀이 진한 색상을 띄게 된다. 분석 결과, 전반적으로 가장 많은 데이터를 포함하는 첫 번째 레이블(현상태유지)에 대한 예측 값이 4,000 이상으로 다른 클래스에 비해 압도적으로 높은 수치를 기록했다. 이는 ‘현상태유지’ 클래스가 데이터 분포에서 67.6%로 가장 큰 비중을 차지하는 특징이 모델에 강하게 반영된 결과입니다. 반면, 네 번째 레이블(낙석제어공법)의 정확한 예측은 각 모델의 성능 차이를 드러내는 주요 지표로 작용했으며, 이는 다수 클래스와 소수 클래스 간의 균형을 반영하는 데 있어 모델별 성능의 차이를 설명한다.
특히 앙상블 기반 알고리즘은 다양한 요인들을 효과적으로 다룰 수 있는 구조적 강점 덕분에 다른 알고리즘에 비해 예측 정확도가 높았다. 이는 CSMS 기초 데이터의 복잡성과 다변성을 잘 반영한 결과로, 대책공법 추천에서 더 높은 신뢰성을 제공할 수 있음을 시사한다. 따라서, 본 연구의 결과는 대책공법 추천 알고리즘의 실효성과 신뢰도를 높이는 데 기여할 수 있는 가능성을 제시한다.

결론 및 토론
본 연구는 대표적인 상관분석 방법인 Cramér’s V 상관계수를 활용하여 CSMS의 기초 조사 데이터 중 비탈면 붕괴를 유발하는 주요 요인들(비탈면 종류, 주변 지형, 지하수, 풍화도, 불연속면 방향성, 비탈면 형상, 측면 현상, 붕괴 이력, 뜬돌, 낙석, 암반 형태, 불연속면) 간의 상관 관계를 분석하고, Random Forest, XGBoost, LightGBM, CatBoost의 앙상블 기반 알고리즘과 DNN, TabNet의 딥러닝 기반 알고리즘을 활용하여 대책공법인 현상태 유지, 활동 하중 경감 공법, 활동 억제 공법, 낙석 제어 공법, 표면 보호 공법, 수리 제어 공법, 기타 공법의 총 7가지 공법에 대한 예측 모델을 도출하였다.
비탈면 붕괴 요인 중 비탈면 형상은 측면 형상, 붕괴 이력, 뜬돌, 불연속면과 고루 높은 관계를 가지지만 반면에 지하수는 다른 요인들 비탈면 종류, 주변 지형, 붕괴 이력, 뜬돌, 낙석, 암반 형태, 불연속면과 가장 낮은 관계를 가가진다. 이는 비탈면 형상은 실제로 가장 높은 비탈면 붕괴의 원인이고 다른 높은 관계성을 가지는 것을 확인할 수 있었으며, 지하수는 비탈면 붕괴의 중요한 요인 중 하나이지만 계절에 대한 고려가 반영하기 어려워 낮은 값을 가진 것으로 확인할 수 있었다. 이를 통해 상관관계가 높은 요인들은 공법 예측 시 핵심 변수로 고려되어야 하며, 이러한 데이터 분석 결과는 예측 모델의 정밀도를 높이는 데 기여할 수 있음을 확인할 수 있었다.
비탈면 대책공법 예측에 대해서는 대체적으로 Random Forest, XGBoost, LightGBM, CatBoost와 LightGBM + CatBoost의 앙상블 기반 알고리즘들이 DNN과 TabNet 기반 딥러닝 기반 알고리즘들보다 높은 성능을 보였으며, 이는 범주형 데이터의 특성상 결정트리 기반의 앙상블 기반 알고리즘이 범주형 데이터의 구분을 직관적으로 처리하기 때문에 관계를 파악하기 유리하며, 앙상블 기반 알고리즘은 각각의 개별 모델이 서로 다른 데이터를 학습하기 때문에 과적합을 방지하여 더 나은 성능을 보였다. 또한 아주 많은 양의 데이터가 아니기 때문에 딥러닝 기반의 알고리즘들이 상대적으로 성능이 좋지 않았을 것으로 보인다. 이는 다양한 요인을 다루는 CSMS 기초조사 데이터 특성을 잘 반영한 결과이다.
본 연구에 활용된 기초조사 데이터는 다수의 인원이 작성함에 따라 일부 기준이 상이하여 데이터의 무결성에 다소 영향을 미칠 수 있었다. 그러나 향후에는 일정한 기준을 정해 데이터를 수집하고 이를 보완한다면, 보다 향상된 결과를 얻을 수 있을 것이다. 또한, 본 연구에서 예측에 사용된 대책공법은 대표적인 상위 분류의 공법들에 기반하였으나, 실제 현장에서는 약 30여 가지 이상의 세부 공법들이 존재한다. 현재 상황에서는 이 모든 공법을 예측 모델에 반영하기 어려운 측면이 있지만, 데이터의 질이 높아지고 무결성이 확보된다면 보다 세부적인 예측이 가능해질 것으로 기대된다. 현재는 보유한 데이터의 특성상 앙상블 기반 알고리즘이 상대적으로 우수한 성능을 보였으나, 향후 데이터의 무결성이 개선되고 더욱 양질의 데이터를 확보하게 된다면, 다른 알고리즘들의 성능 또한 향상될 가능성이 있다.
본 연구는 인공지능 기반 알고리즘을 활용하여 비탈면 붕괴 대책공법을 예측하는 중요한 기틀을 마련하였으며, 이를 통해 비탈면 붕괴 방지에 대한 보다 효과적인 대책을 논의할 수 있는 토대를 제공하였다. 향후 연구에서는 앙상블 및 딥러닝 알고리즘의 성능을 더욱 향상시키기 위해 다양한 변수를 고려하고 데이터셋을 확장하여 고도화된 모델을 적용할 수 있을 것이다. 이를 통해 비탈면 붕괴의 실시간 예측 시스템 개발과 같은 실용적 응용 연구가 이루어진다면, 실제 현장에서 대책공법 선정에 더욱 효과적으로 기여할 수 있을 것으로 기대된다.
