

서 론
광주광역시는 최근 급증하는 포트홀(pothole) 발생으로 인해 도로 인프라의 유지관리 부담이 크게 증가하고 있다. 포트홀은 도로 포장면이 파손되어 패인 구멍을 말하며, 기후 조건, 포장구조의 열화, 지반 특성 등 다양한 요인이 복합적으로 작용하여 발생한다. 그 중 특히 중·대형 차량의 반복적인 하중 작용, 순간적인 충격과 같은 교통 환경 요인이 주요 발생 원인으로 지목되고 있다(Jo et al., 2008; Choi et al., 2016; Ma, 2016; Han, 2020; Lee and Sun, 2020). 산업단지와 물류 중심 도로에서는 이러한 교통 특성이 두드러지며, 실제로 광주광역시에서도 산업단지가 밀집한 광산구 일대를 중심으로 포트홀 발생이 집중되는 경향이 보고되고 있다.
기존 포트홀 관련 연구는 주로 포장 재료나 구조적 거동 분석에 집중되어 있었다. Yang et al. (2008)은 박리방지 첨가제를 혼입한 아스팔트의 수분 민감성 특성을 분석을 위해 간접인장, 동결융해, 크리프 등의 시험을 수행하였다. Kim et al. (2015)은 포트홀이 발생한 파손부분 혼합물을 샘플링하여 점성도 시험, 동적 전단 유동시험, GPC (Gel Permeation Chromatograph) 등을 측정하여 노화특성을 파악하였다. 이후 효율적인 도로 관리와 피해 예방을 위하여 포트홀 예측 또는 포트홀 탐지 등의 다양한 연구가 수행되었다. Kim et al. (2019)은 ○○시의 포트홀, 지반침하, 도로 함몰과 같은 도로 파손을 예측하기 위해 빅데이터와 머신러닝 기법을 이용하였다. 특히, 역학적-확률적 접근방법을 이용하여 주성분 요인을 결정했는데, 역학적 접근방법을 통해 도로 파손에 영향을 미치는 요인으로 교통량, 평균주행속도, 포장상태지수 등 3가지 변수를 도출하였고, 확률적 접근방법을 이용하여 기온, 기압, 적설량, 초상온도, 적설량 등 5개의 변수를 추가적으로 파악하였다. Woo et al. (2024b)은 CNN (Convolution Neural Network) 대신 인간 뇌의 신경망 작동 방식을 모방하여 가볍고 빠른 스파이크 인공신경망(Spiking Neural Network, SNN)을 활용하여 아스팔트 도로의 포트홀을 탐지하는 예측 모델을 제안하였다. Kaggle 오픈 소스의 포트홀 사진 자료 약 500장을 사용하였고, 학습-시험 비율은 약 8:2로 설정하였다. 학습 결과 포트홀이 있는 사진에서 약 86% 확률로 포트홀을 탐지했다. Woo et al. (2024a)은 CNN과 베이지안 확률론(Bayesian Inference)을 결합한 BCNN (Bayesian-CNN)모델을 활용하여 아스팔트 포트홀 예측 모델을 제안하였다. 도로에서 촬영한 이미지는 그림자, 차량 등 노이즈가 많고, 확보할 수 있는 데이터가 적은데, BCNN을 이용하여 약 90% 이상의 높은 예측 성능을 도출했다. Kim et al. (2025)은 CNN, ANN (Artificial Neural Network)를 이용하여 사진 이미지에서 포트홀을 검출하는 예측 모델을 제안하였다. 예측 모델의 성능은 약 60% 정도로 보통 수준의 성능을 나타냈다. Sah and Ahn (2024)는 객체 인식 기술과 초고해상도 이미지 복원 기술(super resolution)을 활용하여 원거리 포트홀 감지 시스템을 제안하였다. 이미지 복원 기술은 세부사항과 질감을 잘 표현할 수 있는 ESRGAN을 활용하였고, 객체 인식은 YOLO (You Only Look Once) 5을 이용하였다. 하지만, 예측모델에 고려된 변수는 도로의 영상 자료들이며, 교통량, 차량 종류, 기후 조건 등이 고려되지 못하였다. 특히 교통량 조사는 현장 계측이나 특정 시점의 조사에 의존하는 경우가 많아, 공간적·시간적 특성을 충분히 반영하지 못하는 한계가 있다. 최근에는 영상 기반 인공지능 기술의 발전으로 다양한 도로영상으로부터 실시간으로 차량 종류를 분류하고 교통 흐름을 분석할 수 있게 되었으며, YOLO 기반 객체 인식 모델은 높은 정확도와 처리 속도로 교통 분석 분야에서 주목받고 있다(Hong and Cho, 2022; Sah and Ahn, 2024; Woo et al., 2024a; Kim et al., 2025; Yudakul and Tasdemir, 2025).
본 연구는 광주광역시 포트홀 및 도로시설 유지 및 관리를 위한 기초 연구로서 YOLO 기반 객체 인식 모델을 활용하여 차량 이동량 및 종류 등을 식별할 수 있는 예측 모델을 제안하는데 있다. 이를 위해 AI Hub, 공공데이터, 자체 촬영 영상을 포함한 대규모 영상 자료를 수집하여 학습데이터를 구축하였고, 이 데이터와 YOLO 모델을 이용하여 영상 자료에 나타나는 객체를 인식하여 중차량으로 분류되는 트럭, 특수차, 버스 등을 검출하였다. 또한 포트홀 발생 지역의 공간적 밀집도와 비교함으로써, 교통 특성이 포트홀 발생에 미치는 영향을 분석하고 향후 유지관리 의사결정에 활용할 수 있는 기초자료를 제시하고자 한다.
연구지역 포트홀 발생
포트홀 발생 지점 및 교통량
광주광역시는 동구, 남구, 서구, 북구, 광산구 5개의 구로 구분된다. 그중 광산구는 하남산단, 평동산단 등 산업단지와 무진대로, 동곡로, 하남진곡산단로 등 자동차전용도로가 밀집해 있고, 물류 이동을 위한 적재 차량과 중형 및 대형 차량 통행이 꾸준히 증가하고 있다. Fig. 1은 2022년부터 2024년까지 광산구 지역에서 나타난 포트홀 발생 위치이다. Fig. 1에서 선은 광주광역시의 도로이며 포트홀이 발생한 지역은 산업단지 또는 물류 이동량과 중대형 차량 통행이 많은 지역이다. 광산구 남부에서 하남진곡산단으로 이어지는 광산구의 주요 도로 중 운수IC사거리, 장수교차로, 선운사거리의 가로구간 교통량은 Table 1과 같다(Gwangju City, 2024). 이 교통량은 2023년도 광주광역시 교통 기초조사 자료로서 도로 상하행으로 구분하여 차량 통행량을 조사한 결과이다. 6개 교차로의 통행량을 승용차, 승합차, 택시, 버스, 화물차, 트레일러, 이륜차로 구분한 결과 승용차 비율이 가장 높았고, 중차량(버스, 화물, 트레일러) 비율은 약 25%에 해당하였다. 또한, 중차량 중에서도 화물 및 트레일러의 비율은 약 90% 이상으로 나타났다.
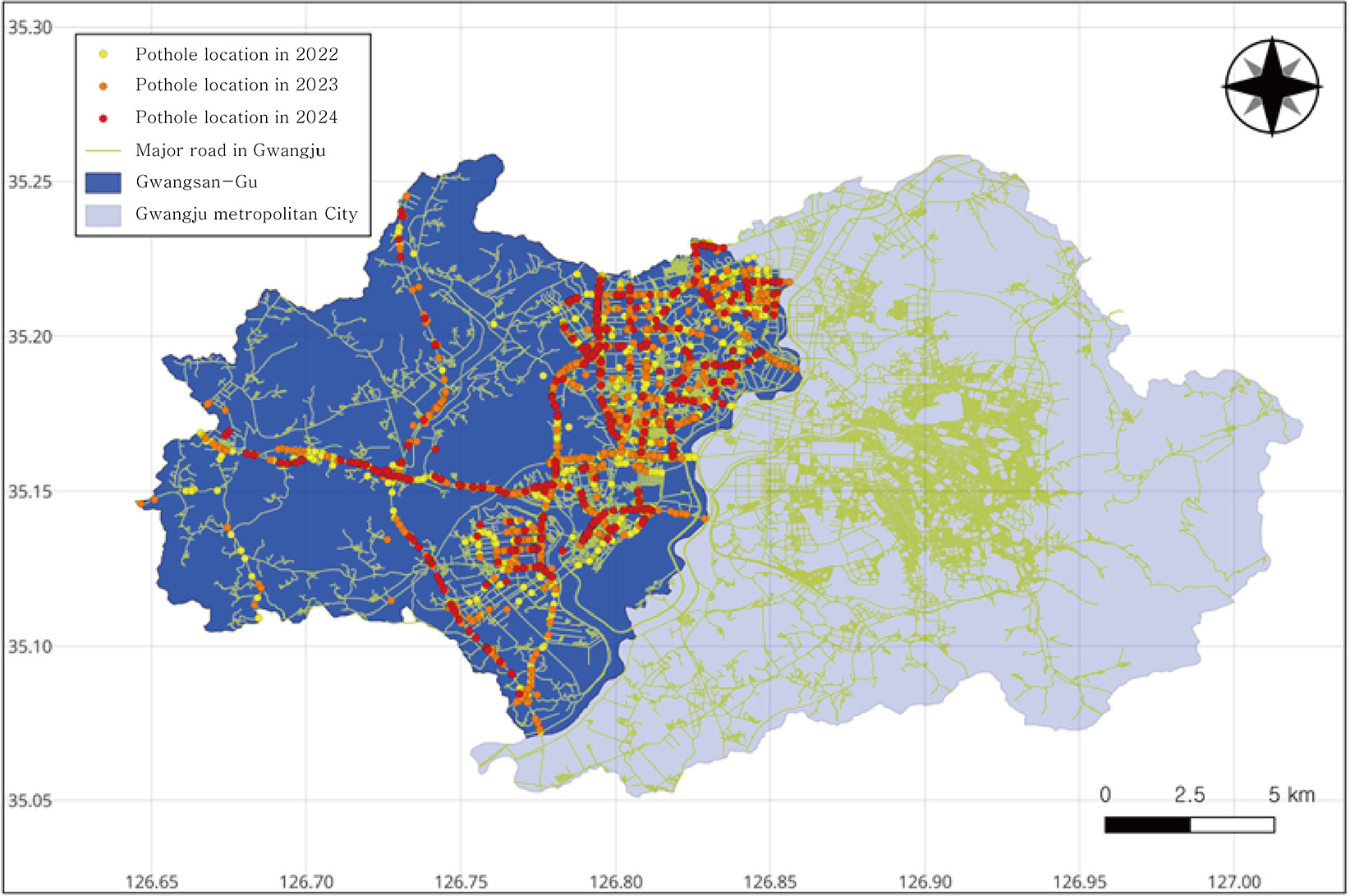
Table 1.
The intersection traffic volume of Gwangsan-gu (Gwangju City, 2024)
기상자료-포트홀 기초 통계분석
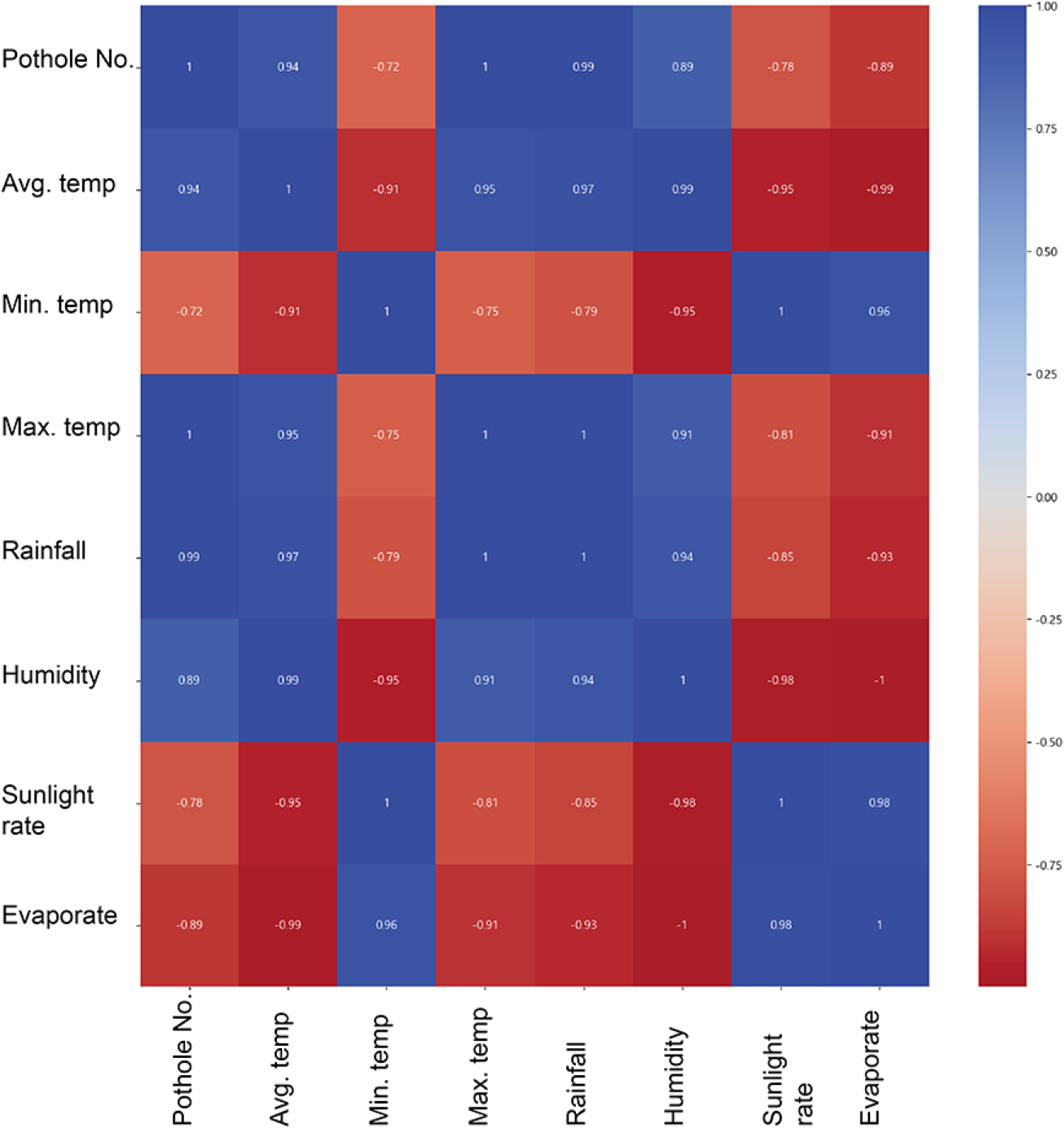
광주광역시 광산구의 포트홀 발생 자료와 기상청의 종관 기상 자료를 카이제곱 분석, 상관 관계 분석하여 광산구 지역 포트홀 발생이 환경요인에 영향을 받는지 조사하였다(Table 2). 8개 변수의 상관관계 분석은 피어슨 상관분석을 사용하였다. 이 방법은 두 변수간의 관계를 -1–1 사이의 수치로 표현한 값이며, -1 또는 1에 가까울수록 상관성이 높고, 0에 가까울수록 상관도는 낮고, 식 (1)을 이용하여 산정할 수 있다.
여기서, n은 샘플 수, xi는 i번째 x의 값, yi는 i번째 y의 값, 는 변수 y의 평균이다. 피어슨 상관계수를 이용하여 8개 변수를 분석한 결과는 Fig. 2와 같고, 포트홀 변수는 나머지 7개의 기상 변수와 높은 상관도를 나타내는 것으로 판단된다.
각 변수가 상호 독립 관계인지, 연관성을 맺고 있는지를 검증하기 위하여 카이제곱 교차분석을 수행하였다. 이 방법은 실제 관찰 빈도와 기대 빈도 간의 카이제곱분포(chi-squared distribution)를 이용하여 통계적으로 검증하는 기법으로 식 (2)와 같다.
여기서, C와 R은 각 행과 열에 속한 관측치의 수, N은 전체 관측치의 수, O는 관찰 빈도를 나타내고, E는 기대 빈도이다. 카이제곱 교차 분석 결과 모두 유의확률 5%를 초과하여 포트홀 발생과 기상 변수는 연관성이 없는 것으로 나타났다(Table 3). 상관관계 분석과 카이제곱 교차분석 결과가 상이한 이유는 분석에 고려된 변수 및 샘플 수가 제한적이며, 공간적 자료 등이 고려되지 못했기 때문인 것으로 판단된다.
Table 2.
The pothole occurrence and weather conditions in Gwangsan-gu, 2022-2024
연구방법
데이터 전처리
본 연구에서 차량 객체 인식을 위하여 AI Hub, 공공데이터, 자체 영상 촬영 자료 등을 통하여 다양한 도로 교통 환경에서의 객체 학습을 진행하였다. 공공데이터는 주행 차량 관점의 특수 차량 형상 데이터, 차량 외관 영상 데이터, CCTV 기반 차량 정보 빛 교통 정보 계측 데이터, 교통 문제 해결을 위한 CCTV 교통 영상 등과 Ultralytics의 COCO (Common Objects in Context), VisDrone (Visual Drone)을 사용하였다. 여기서 COCO는 일상생활에서 흔히 볼 수 있는 물체들을 사람의 눈높이에서 촬영된 이미지들로 구성되어 있으며, VisDrone은 드론과 같은 무인항공기에서 촬영한 항공 이미지 데이터로 구성되었다. 이미지 샘플은 총 1,395,468개이고, 자전거, 개인형 이동장치(personal mobile, PM), 일반차(승용, RV), 버스, 트럭, 중차량 등의 교통수단이 구분 불가능하거나, 해상도가 낮은 자료는 제외하여 총 256,857개를 입력자료로 선정하였다(Table 4). 예측 모델의 탐지 대상 클래스는 사람(person), 자전거(bicycles), PM, 2륜차(motorcycle), 일반차(car), 트럭(truck), 버스(bus), 중차량(special car)로 8종으로 구성하였다. 초기 수집 데이터는 JSON 기반 Bounding Box 형식이며, 모델 호환성과 데이터셋 일관성을 위하여 YOLO/COCO 형식으로 변환하였다. 입력 영상자료의 데이터 불균형과 성능 향상을 위하여 수평반전(miroring), 랜덤 크롭(random crop), 컬러 시프트(color shift) 등의 이미지 증강(augmentation) 전략을 적용하였다. 전체 데이터 중 유사한 영상 자료는 ImagHash 기반의 유사도 분석을 통하여 비슷하거나 중복된 영상자료는 입력자료에서 제거하였다.
Table 4.
The source and classification of data sets for object detection analysis
데이터 학습
학습 방법
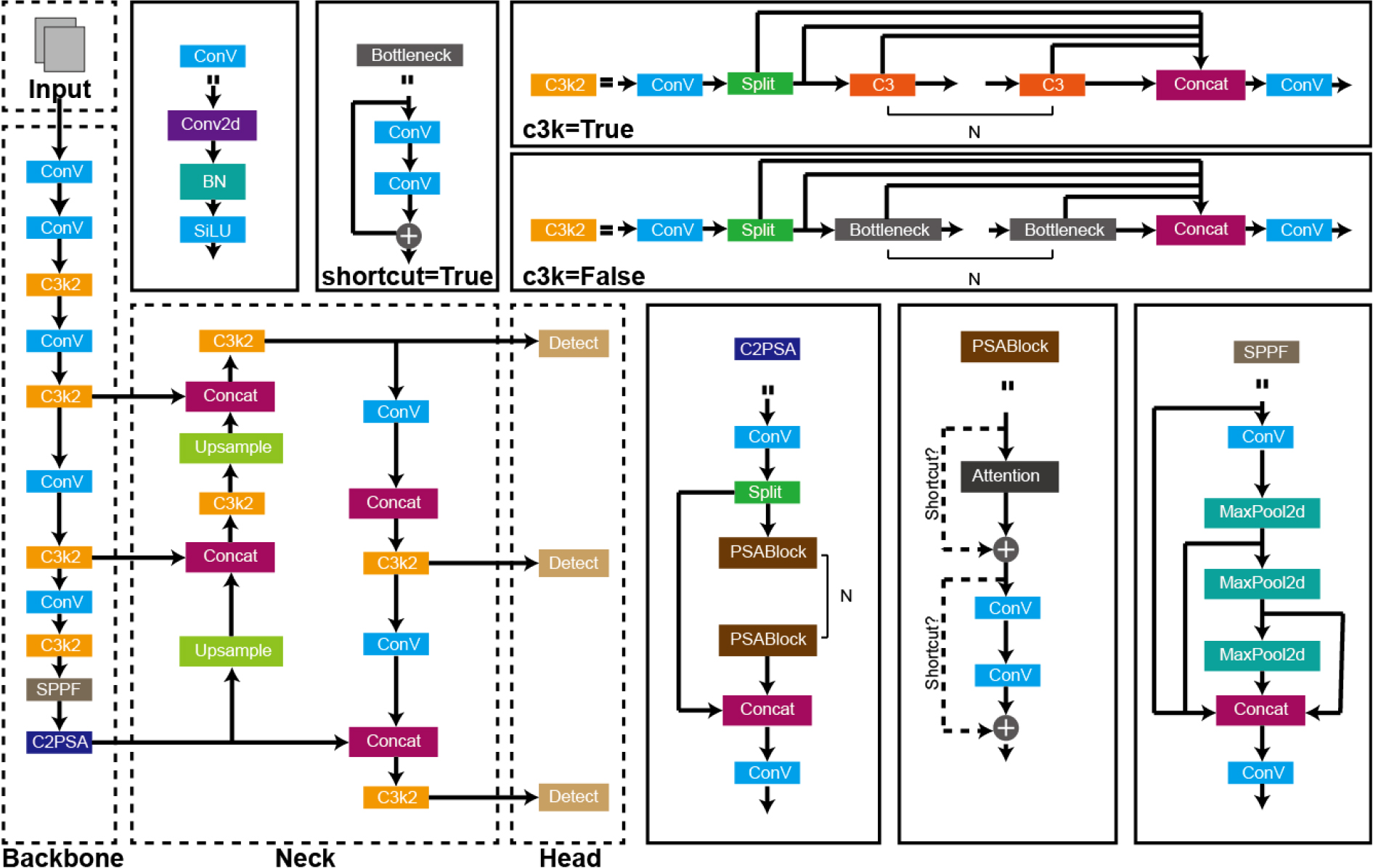
본 연구에서는 차량 객체 인식을 위한 예측 모델은 최신 객체 탐지 모델인 YOLO11을 이용하였다. YOLO11은 탐지, 세분화, 포즈 추정, 추적 및 분류를 포함한 여러 작업에서 최첨단 성능을 제공하는 Ultralytics YOLO 모델이다(Ultralytics, 2025). 이전 YOLO 모델보다 정확도와 처리 속도가 높게 나타났고, On-device AI 환경에서도 안정적인 실시간 탐지가 가능하다. YOLO11의 전체 아키텍처(architecture)는 Fig. 3과 같다. YOLO의 아키텍쳐를 구성하는 서브 네트워크는 입력 이미지로부터 특징 추출(backbone), 특징 융합(neck), 최종 예측(head)으로 3개로 구성되었고, 이 서브 네트워크는 다시 합성곱(Conv) 레이어, Bottleneck, C3k2 (Cross Stage Partial with kernel size 2) 등의 블록들이 반복적으로 배치되어 있는 것이 특징이다(Zhang et al., 2025). 여기서, Backbone은 특징 추출 네트워크로 입력 이미지를 다중 스케일 특징 맵으로 변환하는 역할을 한다. Neck은 Backbone에서 추출된 다중 스케일 특징을 융합하여 더 풍부한 표현을 생성하며, PANet (Path Aggregation Network)과 유사한 구조를 사용한다. Head는 Neck의 출력으로 최종 바운딩 박스, 클래스 확률, 신뢰도를 예측한다. C2PSA 블록은 병렬 공간 주의 메커니즘을 사용하여 작은 객체 탐지를 강화한 블록이다. PSABlock도 병렬 공간 주의 블록으로 특징 맵의 중요한 영역을 강조하는 블록이다. Upsample & Concat은 저해상도 특징을 업샘플링하여 고해상도와 연결하는 블록이다. C3k2는 YOLO11의 핵심으로 CSP (Cross Stage Partial) 구조를 기반으로 커널 크기 2를 사용해서 이미지 처리 효율성을 높였다. SPPF (Spatial Pyramid Pooling Fast)는 Backbone의 말미에 배치되어 다양한 스케일의 풀링(pooling)을 빠르게 수행하는 블록이다.
예측 모델 학습에 사용한 영상 자료의 크기는 416이고, Masaic과 Scale 변환 중심의 데이터 확장 기법을 적용하였다. 학습 반복 횟수는 약 30,000회를 설정하였고, 주간, 야간, 우천 등 다양한 도로 환경 요소를 고려하여 색상, 채도, 명도, 대비 등 color augmentation을 조절하여 학습하였다. 예측 모델의 클래스는 사람, 자전거, 일반차, 트럭, 버스, 오토바이, 중차량, PM 등 8개로 분류하여 구분하였다. 예측 모델은 입력 데이터를 기준으로 크게 2개로 구분하였다. 하나는 Ultralytics의 데이터를 이용하였고, 영상 자료에 나타나는 클래스 객체를 모두 구분하는 것이고, 다른 하나는 공공데이터를 이용하였고 트럭, 일반차, 특수차를 구분하는 것이다.
평가 지표
평가 지표는 시각적 결과물로 확인 할 수 있는 방법으로 레이블 검증(label verification)과 유효성 검사 배치 레이블(validation batch labels)을 사용하였고, 예측 모델의 성능을 정량적으로 나타내기 위하여 정밀도(precision), 재현율(recall), F1-Score, mAP50 (mean Average Precision at 50%), mAP50-95등 5개의 지표를 사용하였다.
레이블 검증은 학습 시 레이블이 올바르게 나타나는지 확인하는 작업이고, 유효성 검사 배치 레이블은 개별 배치에 대한 실제 레이블을 시각화하는 작업이다(Fig. 4). 정밀도는 거짓 검출을 최소화하는 것이 우선순위일 때 중요한 지표로 감지된 객체가 참인지를 나타내며, 재현율은 객체의 모든 인스턴스를 검출하는 것이 중요한 경우 필수적으로 평가해야 하는 지표로 객체의 모든 인스턴스를 식별하는 것을 나타낸다. F1-Score는 정밀도와 재현율의 조화평균이다. mAP50과 mAP50-95는 YOLO11 모델의 성능지표이다. 이 두 지표는 두 박스의 교집합 영역을 두 박스의 합집합 영역으로 나눈 IoU (Intersection over Union)를 이용한다. IoU는 0에서 1의 값을 가지며 IoU가 높을수록 두 박스가 서로 겹치는 면적이 많다는 것을 의미한다. mAP50의 경우 IoU가 0.5 이상인 것, mAP50-95는 IoU가 0.5–0.95인 것을 의미한다. 따라서 mAP50은 넉넉한 오차범위를 갖기 때문에 쉬운 탐지만을 고려한 지표이고, mAP50-95는 다양한 탐지 난이도 수준에서 모델의 성능을 종합적으로 파악할 수 있는 지표이다(Ultralytics, 2025).

연구결과
Ultralytics의 영상 자료를 이용하여 객체 인식 및 분류한 결과 Fig. 5와 같다. 클래스별 객체는 사람 262,465개, 자전거 7,113개, 일반차 43,865, 트럭 9,973개, 버스 6,069개, 오토바이 8,725개를 분류되었다(Fig. 5a). 객체 인식 위치는 영상 자료의 정중앙을 기준으로 다양한 곳에서 인식되었고, 크기의 경우 대부분 작은 객체가 인식된 것으로 나타났다(Fig. 5b and c). 객체 인식 클래스 중 약 78%가 사람이기 때문에 작은 객체가 여러 위치에서 인식되었을 것으로 판단되고, 영상 중앙에 객체가 위치할 경우 예측 모델을 통한 객체 인식이 가장 잘된 것으로 나타났다.

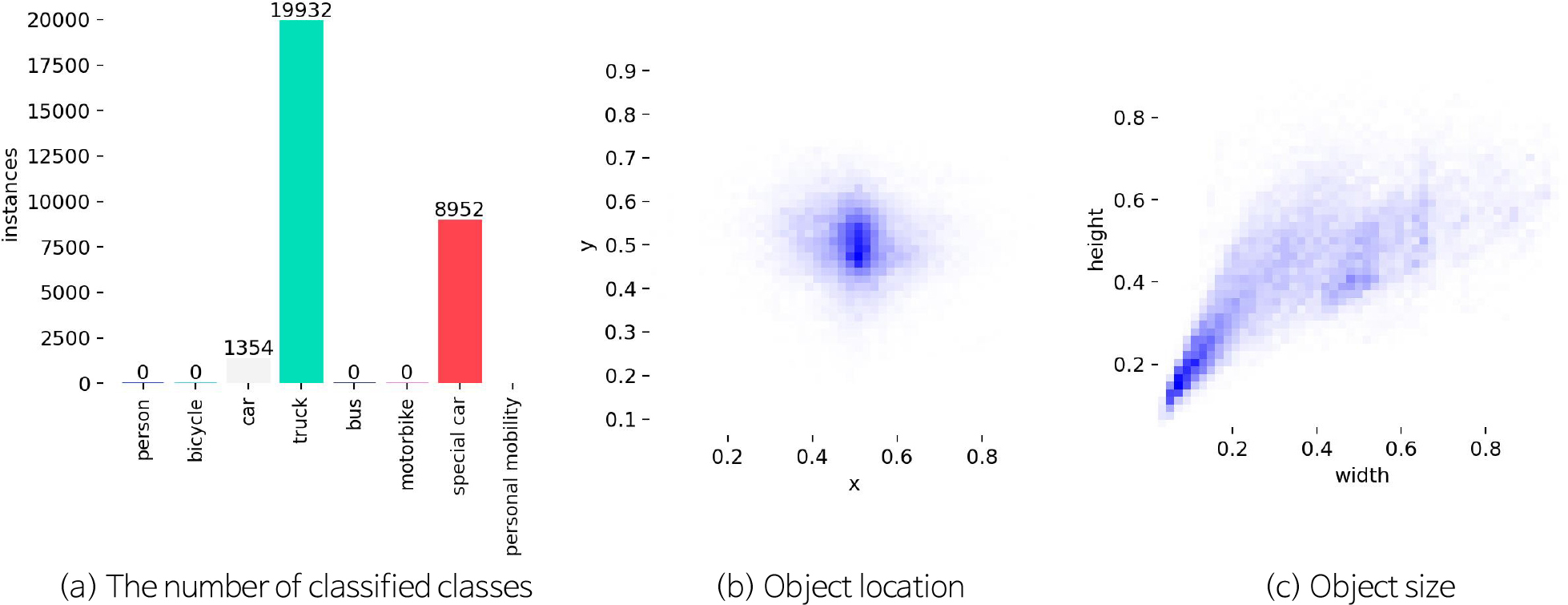
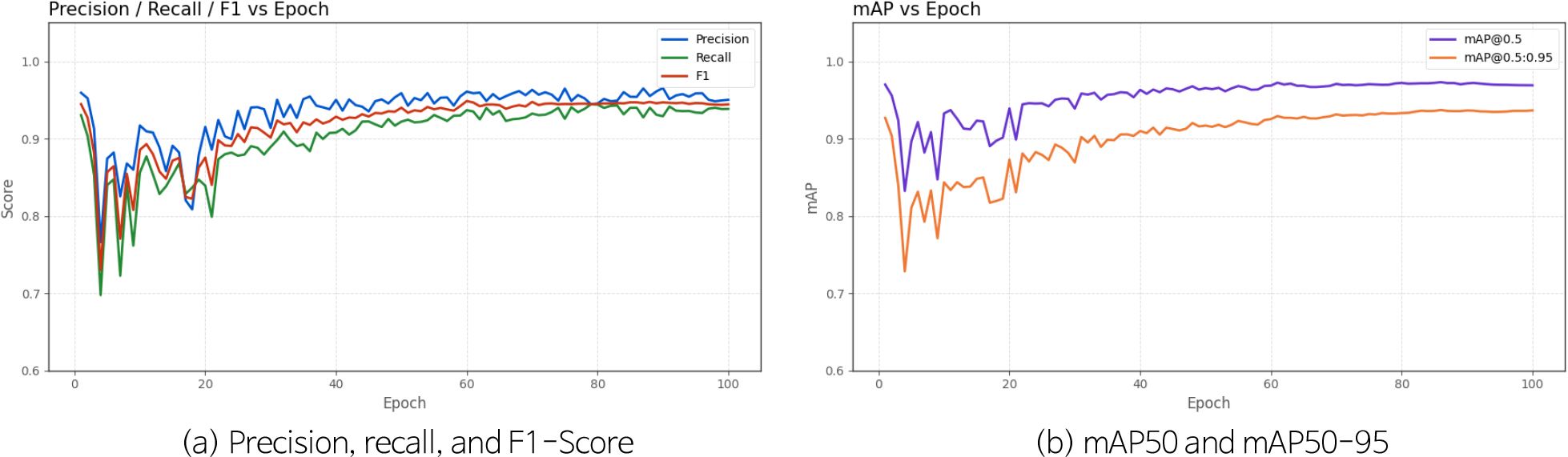
공공데이터의 영상 자료를 이용하여 트럭, 일반차, 특수차를 분석한 결과는 Fig. 6과 같다. 클래스별 객체는 일반차 1,354개, 트럭 19,932개, 특수차 8,952개가 분류되었다(Fig. 6a). 객체 인식 위치는 영상 자료 중앙 근처에 집중되어 나타났고, 크기의 경우 작은 객체부터 큰 객체까지 다양하게 검출되었고, 주로 작은 객체가 많이 분류된 것으로 판단된다. 트럭과 특수차의 경우 영상 자료에 확대되어 촬영되었거나, 먼 거리에서 가까운 거리로 온 경우 크게 촬영된 경우가 있어 객체 인식 크기가 다양하게 나타난 것으로 판단된다. Fig. 7은 객체 인식 예측 모델의 학습에 따른 성능 평가 지표 결과이다. Fig. 7a는 예측 모델 훈련 횟수에 따른 정밀도, 재현율, F1-Score에 대한 결과이고, Fig. 7b는 예측 모델 훈련 횟수에 따른 mAP50과 mAP50-95의 결과이다. 모든 평가지표들이 20회 반복 이후 안정적으로 수렴하는 것으로 나타났고, 정밀도는 약 0.95, 재현율은 약 0.92, F1-Score는 0.94, mAP50은 약 0.96, mAP50-95는 약 0.91으로 높은 성능을 나타냈다.
결 론
본 연구는 광주광역시 중 산업단지와 중차량 통행량이 집중된 광산구의 포트홀 발생 현황을 분석하고 이를 효율적 관리하기 위한 기초연구로서 YOLO11 기반의 객체 인식 모델을 활용한 차량 통행 분석 기초 모델을 제안하였다. 이를 위하여 첫째, 광산구에서 포트홀 발생 밀집도를 확인하고, 기상 변수와 기초 통계 분석을 수행하였다. 그 다음, YOLO11을 이용하여 수집한 데이터를 이용해 객체 인식 예측 모델의 성능을 분석하였다.
광산구 지역 포트홀 발생 위치는 하남산단, 평동산당 등 산업단지와 주요 물류 이동 경로에 집중되어 있음을 확인하였다. 기상 요인과 상관관계 분석 결과 포트홀 변수와 기상 변수 7개 간의 상관계수는 높게 나타났으나, 카이제곱 교차 분석 결과에서는 포트홀과 기상 변수 7개는 연관성이 없는 것으로 나타났다. 이는 기상 변수 외의 변수들이 연관되어 있을 수 있다는 것을 나타낼 수 있으나, 고려된 변수 및 샘플 수가 적어 정교한 판단을 수행하기에는 무리가 있다.
다양한 도로 교통환경에서의 객체 인식을 위해 AI Hub, 공공데이터, 자체 촬영 영상 등을 확보하여 학습 데이터를 구축하고 데이터 전처리 과정에서 이미지 증강 기법을 적용해 모델의 강건성을 확보하였다. 객체 인식을 위해 트럭, 특수차, 버스, 일반차 등 8개 클래스로 객체를 분류하였고, 그 중 트럭, 특수차, 버스를 중차량으로 분류하였다. 예측 모델을 통해 객체를 분류한 결과 정밀도 0.95, 재현율 0.92, F1-Score 0.94, mAP50은 0.96, mAP50-95는 0.91로 매우 우수한 객체 인식 성능을 나타냈다. 도로 내 영상과 이 예측 모델을 통하여 교차로를 통과하는 중차량을 효과적으로 탐지 및 분류할 수 있을 것으로 판단된다. 향후 본 모델을 통하여 수집된 중차량 통행 데이터, 기상자료, 포트홀 발생 위치의 공간적 밀집도를 연계 분석한다면 선제적인 도로 유지관리 및 보수 의사결정에 중요한 기초 자료로서 활용될 수 있을 것으로 판단된다.
