

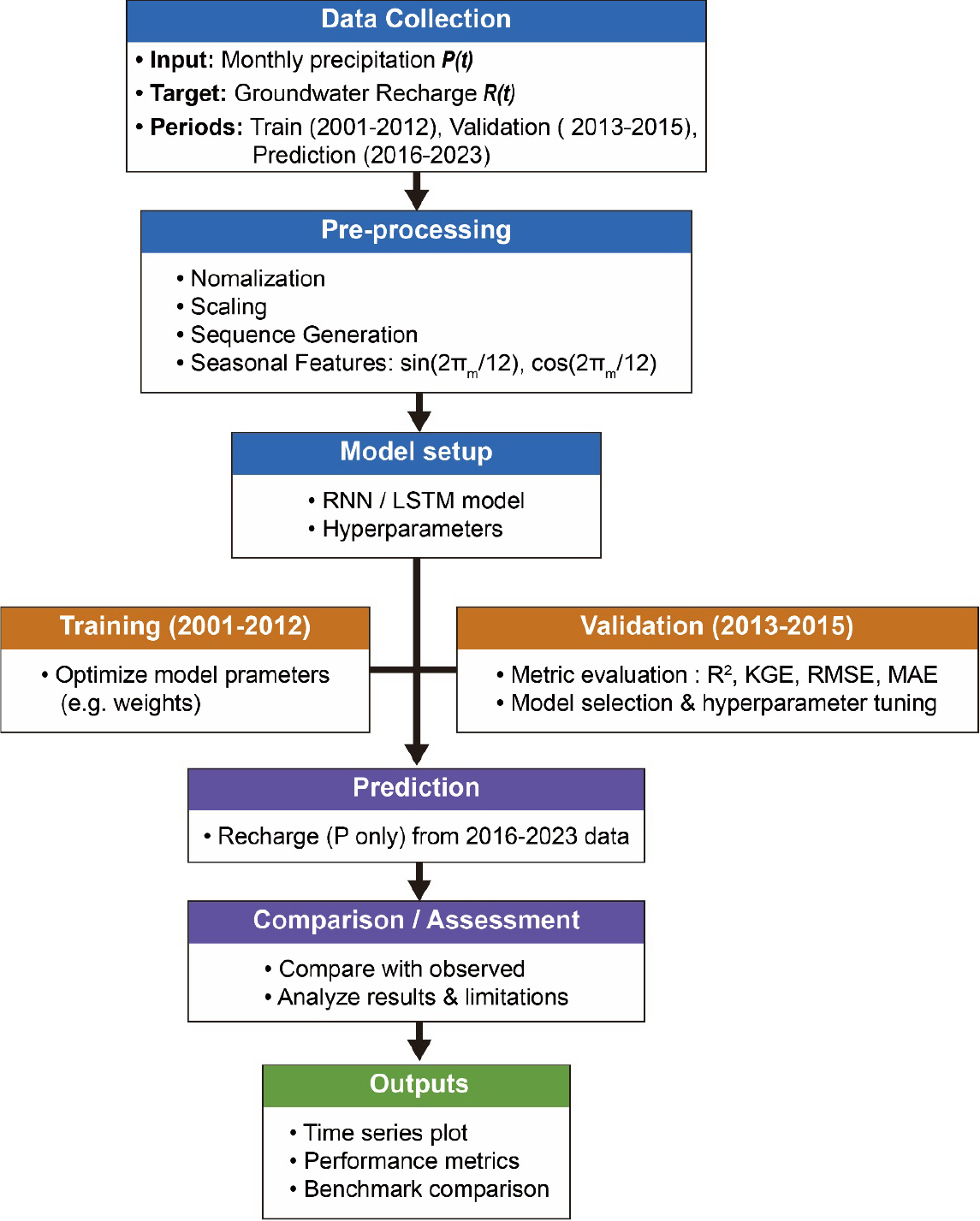
서 론
연구방법
연구 대상 지역 및 자료 수집
딥러닝 예측 모델 구성
자료 구축 및 전처리
검증 단계 및 평가 지표
결과 및 고찰
딥러닝 모델 학습 및 검증 결과
2016-2023년 지하수 함양량 예측 변화
예측 결과의 하천 유지용수 활용 시나리오 고찰
결론 및 토의
서 론
지하수는 가뭄 등 극한 수문 상황에서 하천의 유량을 유지하는 데 핵심적인 역할을 하는 자원으로서, 지속가능한 물 관리 전략 수립에 필수적이다. 충청북도 청주 지역의 무심천 유역은 평소 유량이 적어 가뭄 시 하천 유지용수 확보에 어려움을 겪고 있으며, 이에 대한 대응 방안으로 지하수의 활용 가능성이 주목받고 있다. Chung et al. (2017a)은 무심천 유역의 지하수를 인위적으로 취수하여 하천 유지용수로 공급하는 시나리오를 제시하였는데, 극한 가뭄이었던 2015년의 모의 결과 지하수 공급을 통해 하천 월유출량이 최대 68%까지 증가하여 연평균 강수량의 약 24%에 해당하는 290 mm의 추가 유량을 확보할 수 있는 것으로 나타났다. 이는 지하수 자원이 가뭄 시 고갈되기 쉬운 지표수에 비해 하천 유지용수 공급의 효과적인 대안이 될 수 있음을 시사한다. 이러한 시나리오를 실현 가능하게 실행하기 위해서는 대수층의 공급원인 지하수 함양량에 대한 신뢰성 있는 추정이 선결되어야 한다. 다시 말해, 지하수로 하천 유량을 보충하려는 정책을 펼치기 전에, 미래 기후와 강수 변동 속에서 해당 유역의 지하수 함양량에 대한 정량적 파악이 필요하다. 지하수 함양량 예측과 관련하여 Ware et al. (2023)은 SWAT (Soil and Water Assessment Tool)-MODFLOW 모형과 지하수위 변동법을 이용한 시공간적 지하수 함양량 분포에 관한 연구를 수행하였으며, 소유역별 월별 함양량의 추정을 위해 유역수문모형의 활용이 중요하다는 것을 강조하였다. Gassman et al. (2014)과 Al Khoury et al. (2023)은 유역수문모형 SWAT을 이용하여 수문성분을 분석하고 이를 활용한 다양한 적용방안을 제시한 바 있다. 이처럼 기존 물 관리 분야에서는 강우-유출 및 지하수 함양을 예측하기 위해 주로 물리 기반의 수문모형을 활용해왔다. 특히 SWAT-MODFLOW모형(Kim et al., 2008)과 같은 유역 통합 수문모형은 토양, 식생, 지형 및 지하수층 특성을 모두 고려하여 수문 순환 과정을 정밀하게 모의할 수 있다. 이러한 모형은 물리적 인과관계에 근거한 해석을 제공하므로 결과에 대한 신뢰성과 설명력이 높고, 다양한 관리 시나리오(예: 토지이용 변화, 기후변화, 지하수 이용 증감 등)에 대한 예측 시나리오 분석이 가능하다는 장점이 있다. 실제로 Chung et al. (2017a)의 연구에서는 SWAT-MODFLOW 통합모델을 통해 무심천 유역의 물수지를 면밀히 분석함으로써 지하수를 활용한 하천 유지용수 공급 잠재량을 정량적으로 평가하였다. 그러나 이와 같은 통합 모형을 활용하려면 많은 노력과 시간이 소요된다. 유역 규모의 통합 수문모델은 수문인자에 대한 수십 개 이상의 모형 매개변수 보정이 필요하고, 모형의 불확실성을 검증하기 위한 민감도 분석 과정도 복잡하다. 또한 모형 구축 및 시뮬레이션에 대규모 연산이 요구되어, 긴 모의 기간이나 복수의 시나리오를 고려할 경우 실행 시간이 상당히 길어질 수 있다. 정책 수립 초기에 여러 대안을 신속히 평가해야 하는 상황에서 이처럼 무거운 모형은 활용에 한계가 있으며, 비전문가가 이해하거나 운용하기에도 어려움이 따른다. 따라서 물리 기반 모형의 강점을 유지하면서도, 보다 신속하고 단순한 입력으로 함양량을 예측할 수 있는 대안적 접근이 필요하다.
이러한 한계를 보완하기 위해 최근 딥러닝(deep learning)을 포함한 데이터 기반 예측모형에 대한 관심이 높아지고 있다(Jo and Jung, 2024). 데이터 기반 모형은 과거 자료로부터 비선형 관계를 학습하여 비교적 짧은 시간에 예측값을 산출할 수 있으므로, 물리 과정을 모두 상세히 모사하지 않더라도 목적 출력(예: 유출량, 지하수위, 함양량)의 변동성을 재현하는 데 활용될 수 있다. 예를 들어 Chung et al. (2017b)은 제주도 지역을 대상으로 인공신경망(Artificial Neural Network, ANN)을 이용한 월별 지하수위 예측모형을 제시하였고, Park and Chung (2020)은 순환신경망(Recurrent Neural Network, RNN) 계열의 LSTM (Long short-term memory) 기법을 적용하여 지하수 관측자료의 변동성을 분석하였다.
본 연구의 목적은 무심천 유역에서 강수량 기반 입력만으로 월별 지하수 함양량을 어느 정도 재현할 수 있는지 평가하고, 이를 통해 물리 기반 모델링을 보완할 수 있는 실용적 예측 도구로서의 가능성을 확인하는 데 있다. 이를 위해 RNN과 LSTM 모형을 구성하고, 검증 기간에서 복수 성능지표를 종합적으로 비교하여 최적 모형을 선정한 뒤 예측(2013–2015)을 수행하였다.
연구방법
연구 대상 지역 및 자료 수집
본 연구의 대상인 무심천 유역은 충청북도 청주시를 흐르는 소유역으로, 배후에 소규모 산지가 있고 하류부는 도시화된 분지 지형을 보인다. 하도의 길이는 약 34.50 km, 유역면적은 약 198 km2이다. 청주시 상당구 낭성면 남부 산지에서 발원하여 남서쪽으로 흐르다가 가덕면 서부에서 북서쪽으로 방향을 바꾸어, 청주 시가지로 유입된 후 시가지 중심부를 지나 미호천에 합류한다.
지하수 함양량(Recharge) 자료의 경우 직접 관측이 어렵기 때문에, 본 연구에서는 SWAT-MODFLOW 통합모의 결과(Chung et al., 2017a)를 이용하였다. 즉, 무심천 유역에 대한 SWAT-MODFLOW 모형 결과를 이용하여 2001–2015년 기간의 함양량 자료를 산정하고, 산출된 월별 지하수 함양량 값을 딥러닝 모델의 목표 출력(target) 데이터로 활용하였다. 이렇게 하면 물리 모델이 제공하는 함양량 산출치를 학습 데이터로 활용함으로써, 딥러닝 모델이 물리 기반 모형의 거동을 모사하도록 훈련될 수 있다. 최종적으로 학습에 사용된 자료 쌍은 월별 유역 평균 강수량(입력)과 해당 월의 지하수 함양량(출력)으로 구성되며, 총 180개월분의 데이터가 확보된다. 이렇게 학습된 LSTM모델을 이용하여 2013–2015년의 지하수 함양량을 예측하였다(Fig. 1).
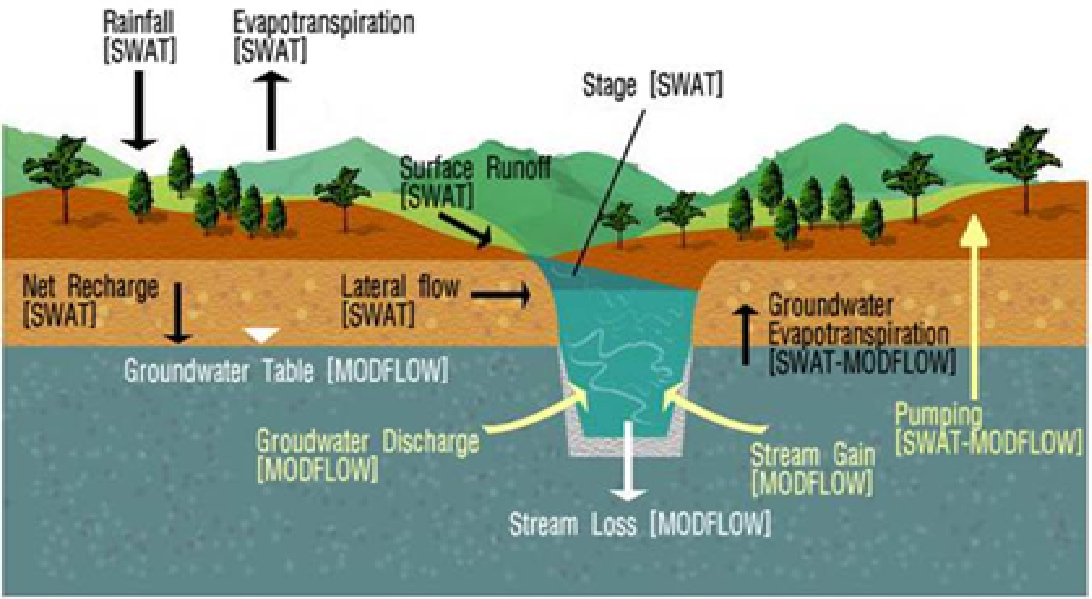
본 연구에서 사용한 SWAT-MODFLOW 모형(Kim et al., 2008)은 SWAT (Soil and Water Assessment Tool)모형(Arnold and Fohrer, 2005)의 지하수 부분을 3차원 지하수 유동모형인 MODFLOW (McDonald and Harbaugh, 1988)로 대체시키고 지표수 수문성분과 지하수 유동을 연계시킨 유역단위의 지표수-지하수 통합모형이다(Fig. 2).
딥러닝 예측 모델 구성
본 연구에서는 무심천 유역의 지하수 함양량을 예측하기 위한 딥러닝 모델로 RNN 및 LSTM 기반 시계열 예측 모형을 구성하였다. 모델 구현은 Python 기반 딥러닝 라이브러리를 이용하여 수행하였으며, 입력 시퀀스를 은닉 상태로 요약한 뒤 출력층에서 월 함양량을 산정하도록 구조를 설계하였다.
입력 변수는 해당 월 강수량과 시차 강수량(Lag1–Lag6), 이동평균(MA3, MA6, MA12), 그리고 계절성 항(sinm, cosm)으로 구성하였다. 이는 이전 강수 및 누적 효과가 월별 함양 변동에 영향을 줄 수 있다는 점을 반영하기 위한 것으로, 강수량만을 기반으로 예측력을 최대화하는 입력 조합을 탐색하였다. 모형 학습에는 Adam optimizer를 사용하였고, 손실함수는 평균제곱오차(MSE)를 최소화하도록 설정하였다.
RNN은 시계열 자료의 순차적 의존성을 표현할 수 있으나, 입력과 출력 사이의 시차가 길어질 경우 과거 정보가 충분히 전달되지 못해 학습이 어려워질 수 있다. 이러한 장기 의존성 학습의 어려움을 완화하기 위해 LSTM이 제안되었으며, LSTM은 입력·망각·출력 게이트와 셀 상태를 통해 중요한 정보를 선택적으로 유지하도록 설계된 구조이다(Hochreiter and Schmidhuber, 1997). LSTM도 RNN처럼 연속된 체인과 같은 구조를 가지고 있으나 하나의 모듈에 4개의 층이 서로 정보를 주고 받도록 고안되어 있다. LSTM의 핵심은 셀상태(cell state)를 통해 정보를 보존할지 모두 버릴지 결정하고 보존한다면 어떤 것을 저장할지 결정하는데 있다. 저장된 정보에 의해 현재의 정보를 업데이트 한 후 역시 셀상태에 따라 활성함수에 의해 출력을 결정한다.
한편, 구축된 신경망 모델의 성능을 평가하기 위해 여러 지표를 활용하였다. 결정계수(R2)와 Nash-Sutcliffe 효율계수(NSE)는 예측된 함양량이 실제 값(모형 기반 추정치)에 얼마나 부합하는지를 나타내는 지표로 사용되었다. 이와 함께 평균절대오차(MAE)와 RMSE를 산출하여 예측 오차의 크기를 정량적으로 평가하였다. 특히 NSE의 경우 수문 모델 성능 평가에 널리 쓰이며, 1에 가까울수록 예측이 정확함을 의미한다. 본 연구에서는 검증기간(2013–2015년)에 대해 NSE, R2등이 0.8 이상으로 나타나는 것을 모델 목표 성능으로 설정하였다. 이는 문헌에 보고된 유사 모델의 성능 범위를 고려한 값으로, 만약 해당 기준에 미달할 경우 모델 구조나 입력 변수를 조정하는 방식으로 개선을 시도하였다.
선행 연구에서는 모형 성능 평가 시 결정계수 기준을 제시하기도 한다. 예를 들어, 유역 규모 수문모의의 경우 R2가 0.60 이상(동시에 NSE 0.50 이상 등)일 때 만족(satisfactory) 수준으로 평가할 수 있다는 지침이 보고되었다(Moriasi et al., 2007, 2015). 다만 R2는 상관 기반 지표로 편향이나 스케일 오차에 둔감할 수 있어, 단일 지표만으로 적합도를 판단하지 말아야 한다(Legates and McCabe, 1999).
또한 Donigian (2002)은 HSPF 적용 사례를 바탕으로 월 단위 모의에서 R2 값이 0.6–0.7이면 fair, 0.7–0.8이면 good, 0.8–0.9이면 very good 수준으로 해석할 수 있다는 일반적인 기준을 제시하였다. 이 기준 역시 자료 품질, 시간해상도, 적용 목적에 따라 조정되어야 한다. 위의 R2 등급 기준은 일반적인 참고 지침이며, 본 연구의 모델 선정은 R2뿐 아니라 KGE, RMSE, MAE를 함께 고려하여 수행하였다. 여기서 RMSE는 Root Mean Square Error, MAE는 Mean Absolute Error, NSE는 Nash–Sutcliffe Efficiency, KGE는 Kling–Gupta Efficiency를 의미한다.
자료 구축 및 전처리
본 연구에서는 2001–2012년 월 단위 강수량·함양량 관측 자료를 학습에 사용하고, 2013–2015년을 예측 구간으로 설정하여 양방향 RNN과 양방향 LSTM을 PyTorch로 구현하였다. 기준 시점은 2012년 12월이며, 예측 대상은 월 함양량이다. 입력 특징은 당월 강수량, 시차 강수량(Lag1–Lag6), 이동평균(MA3, MA6, MA12), 월 주기성(sinm, cosm)으로 구성된 탐색 공간에서 조합을 자동 생성하여 사용하였다(Table 1).
Table 1.
Input feature combinations for the prediction models
입·출력 변수는 MinMaxScaler로 0–1 구간 정규화하였다. 입력 피처 조합과 하이퍼파라미터는 자동 탐색으로 결정하였으며, 학습 데이터 일부를 검증용으로 분할해 조기종료를 적용하고, 검증 손실 최소 가중치를 복원한 뒤 예측 구간 성능(R2, KGE, RMSE, MAE 등)을 기준으로 최적 모델을 확정하였다(Table 2).
Table 2.
Notation and hyperparameters used in this study
| Symbol | Definition |
| h | Number of hidden units |
| L | Number of recurrent layers |
| d | Dropout rate |
| lr | Learning rate |
KGE는 다음과 같이 정의된다.
sinm과 cosm은 월 m(1–12)을 12개월 주기로 각도화한 계절성 입력으로, 각각 sin(2π m/12)와 cos(2π m/12)로 계산하였다. 이 변환은 12월과 1월처럼 달의 연속성을 보존하면서 계절적 위상 차이를 모델이 학습하도록 돕는다. RNN은 양방향(bidirectional) Elman RNN으로 구현하였다(Elman, 1990; Schuster and Paliwal, 1997). 입력은 시점 t의 단일 스텝 피처 벡터(당월 강수, 시차 Lag1–Lag6, 이동평균 MA3/MA6/MA12, 계절성 sinm, cosm의 조합)이며, many-to-one 방식으로 당월 함양량을 예측한다. RNN은 tanh 기반의 단순 재귀 구조로 파라미터 효율이 높지만, 장기 의존 학습에서 기울기 소실 문제가 보고되어 있다(Bengio et al., 1994). 하이퍼파라미터는 h ∈ {64, 128, 256}, L ∈ {2, 3, 4}, dropout ∈ {0.0, 0.2}, 학습률 ∈ {10-3, 5 × 10-4, 10-4}에 대해 그리드 탐색으로 결정하였다.
RNN의 은닉 상태 갱신과 출력 산출은 다음과 같이 정의되며, 양방향 구조에서는 정·역방향 은닉을 결합하여 최종 출력을 구한다.
여기서, 는 시점 t의 단일 스텝 피처 벡터 는 은닉 상태, 는 당월 함양량 예측치이며, 는 학습되는 가중치이다. 식 (4)는 양방향(bidirectional)에서 정방향 와 역방향 를 연결(concatenate)하여 를 구상하고, 이를 통해 many-to-one 출력 를 계산함을 나타낸다(bi는 bidirectional, f는 forward, b는 backward).
LSTM은 입력·망각·출력 게이트를 통해 정보를 선택·보존함으로써 장기 의존성 학습의 어려움을 완화하도록 설계된 구조이다(Hochreiter and Schmidhuber, 1997). 본 연구의 LSTM은 양방향으로 구현하였으며, 입력 구성·학습 프로토콜은 전술한 공통 절차를 따른다. 하이퍼파라미터는 h ∈ {64, 128, 256}, L ∈ {2, 3, 4}, dropout ∈ {0.0, 0.2}, 학습률 ∈ {10-3, 5 × 10-4, 10-4}에 대해 그리드 탐색으로 결정하였다. 손실함수는 MSE, 최적화는 Adam을 사용하였고(Kingma and Ba, 2015), 학습 데이터의 15%를 검증용으로 분리한 뒤 조기종료(early stopping, patience = 300)를 적용하였다. 역정규화 이후 음수 예측값은 0으로 절단하여 물리적 제약(비음수)을 반영하였고, 검증 손실 최소 + 예측 구간(2013–2015) R2 최대 기준으로 최적 모델을 확정하였다.
LSTM에서 는 셀 상태(장기 기억)이며, 는 출력 게이트로서 시그모이드 함수로 계산되는 0–1 값으로 가 얼마나 출력으로 노출될지를 조절한다(와 는 각각 입력·망각 게이트, 는 후보 기억). 이어지는 절차는 RNN과 동일하다. 입력 구성(단일 스텝 피처 벡터), 정규화(MinMax), 학습 설정(Adam+MSE), 검증 분할(학습 데이터의 15%), 조기종료(patience = 300), 역정규화 후 비음수 클리핑(음수 예측값은 0 처리), 그리고 하이퍼파라미터·피처 조합에 대한 그리드 탐색을 적용하였으며, 검증 손실 최소 가중치를 복원한 뒤 예측 구간(2013–2015)의 최대 R2 기준으로 최적 모델을 확정하였다.
검증 단계 및 평가 지표
학습 구간(2001–2012)과 예측 구간(2013–2015)에 대해 R2, RMSE, MAE, KGE 네 지표로 성능을 평가하였다. 모든 지표는 역정규화된 예측값을 사용하며, 물리적 비음수 제약을 반영하기 위해 음수 예측값은 0으로 절단하였다.
최적 모델 선정은 단일 지표에 의존하지 않고 R2, KGE, RMSE, MAE를 종합적으로 고려하였다(Table 3). 또한, 하이퍼파라미터(은닉 유닛 수 h, 입력 시퀀스 길이 L, dropout 비율 d, 학습률 η 등)는 검증 구간에서의 복수 성능지표를 기반으로 탐색하여 최적 조합을 선정한 뒤, 해당 최적 설정으로 최종 모델을 구성하였다.
Table 3.
Definitions, equations, and interpretation of model performance metrics
R2는 관측 함양량의 변동을 모델이 얼마나 설명하는지를 나타내고(Montgomery, 2012), RMSE와 MAE는 예측값이 실제값에서 얼마나 벗어났는지(절대 오차 규모)를 보여준다(Willmott and Matsuura, 2005; Chai and Draxler, 2014). KGE는 상관(r)·변동성 비율(α)·평균 편향(β)을 통합한 지표로, 오차의 형태·스케일·편향까지 함께 진단한다(Gupta et al., 2009; Kling et al., 2012). 네 지표를 함께 보면 전 기간에서 예측의 일관된 정확도, 과적합 여부(학습 대비 예측 성능 저하), 그리고 성능 저하의 원인(상관 부족·변동성 불일치·평균 편향)까지 종합적으로 평가할 수 있다.
결과 및 고찰
딥러닝 모델 학습 및 검증 결과
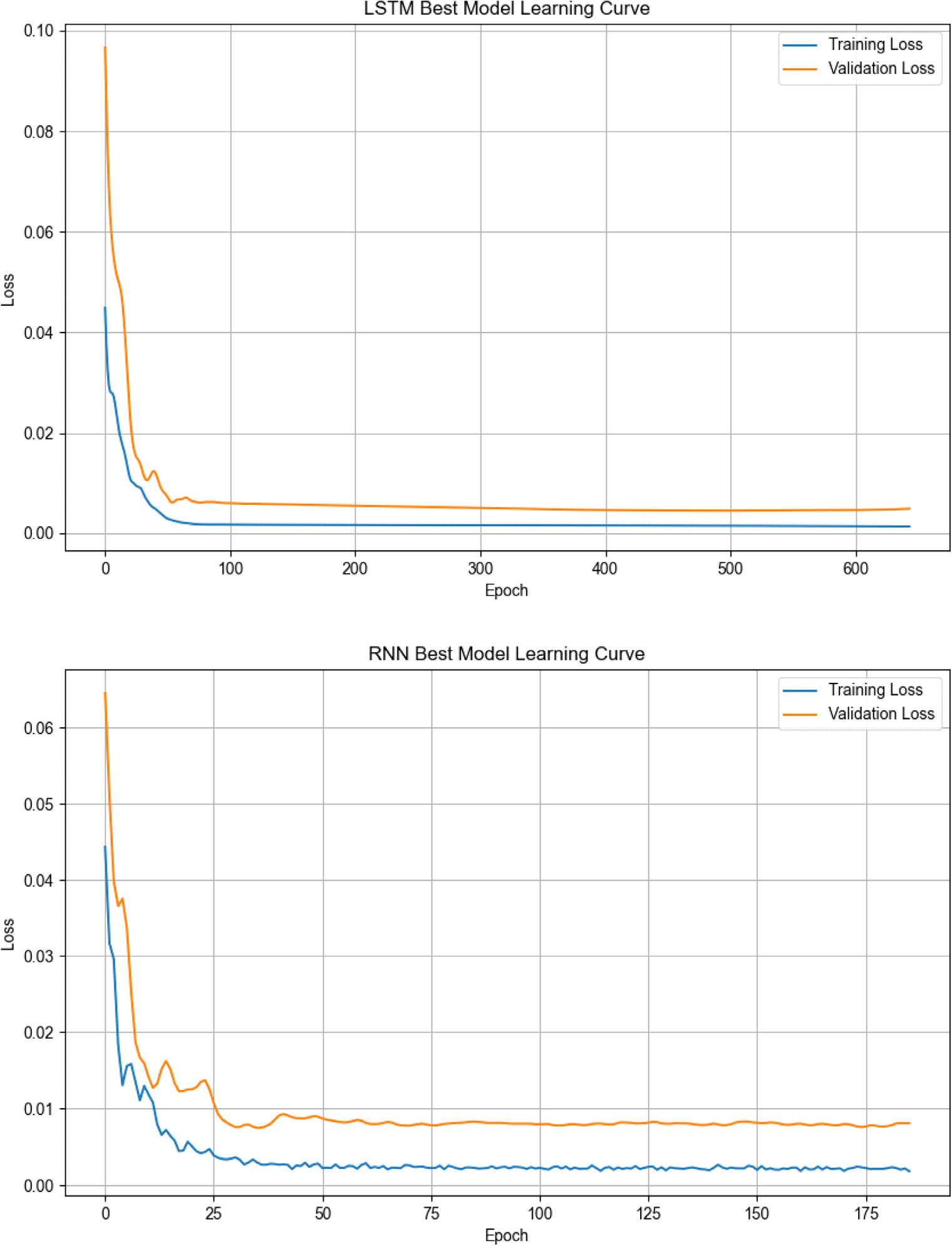
학습을 위해 SWAT-MODFLOW모형을 이용하여 산정된 결과를 이용하여 2001년 1월 1일–2015년 12월 31일의 일별 강수량 및 지하수 함양량 데이터를 월별 합계로 집계하였다. 이를 통해 월 단위의 강수량(mm)과 함양량(mm) 데이터를 생성하였다. 딥러닝 입력은 월 강수량 단일 값이 아니라, 함양의 지연 반응과 계절성을 반영하기 위해 당월 강수, 시차 강수(Lag1–Lag6), 이동평균(MA3, MA6, MA12), 월 주기성(sinm, cosm)으로 구성된 피처 조합 탐색 공간에서 자동 생성·선정하였다. 입·출력 변수는 MinMaxScaler로 0–1 정규화하였고, 손실함수는 MSE, 최적화는 Adam을 사용하였다. 또한 학습 데이터의 15%를 검증용으로 분리한 뒤 조기종료(early stopping, patience = 300)를 적용하였으며, 역정규화 이후 음수 예측값은 0으로 절단하여 함양량의 비음수 물리 제약을 반영하였다. 최적 모델은 검증 손실 최소 가중치를 복원한 뒤 예측 구간(2013–2015) 성능(R2 등)을 기준으로 확정하였다. 또한, 최적 LSTM 및 RNN 모델의 학습 과정에서 훈련 손실과 검증 손실이 안정적으로 수렴하는 양상은 학습 곡선에서 확인할 수 있다(Fig. 3).
학습이 완료된 후 학습 구간(2001–2012)과 테스트 구간(2013–2015)에 대해 관측값(모형 결과)과 예측값을 비교하였다(Fig. 4). 전 기간에 대한 관측값 대비 예측값의 산점에서 대체로 예측이 실제 관측 경향을 잘 반영하는 것으로 나타났으며, 특히 강수량이 많은 여름철의 함양량 첨두값도 비교적 잘 재현하였다. 또한 강수량이 적은 건기에는 함양량이 거의 0에 가까움을 예측하였다. 예측 성능을 정량적으로 평가하기 위해 결정계수(R2), KGE, 평균제곱근오차(RMSE), 평균절대오차(MAE)의 네 가지 지표를 계산하였다. 학습 구간 성능은 Table 4와 같다.
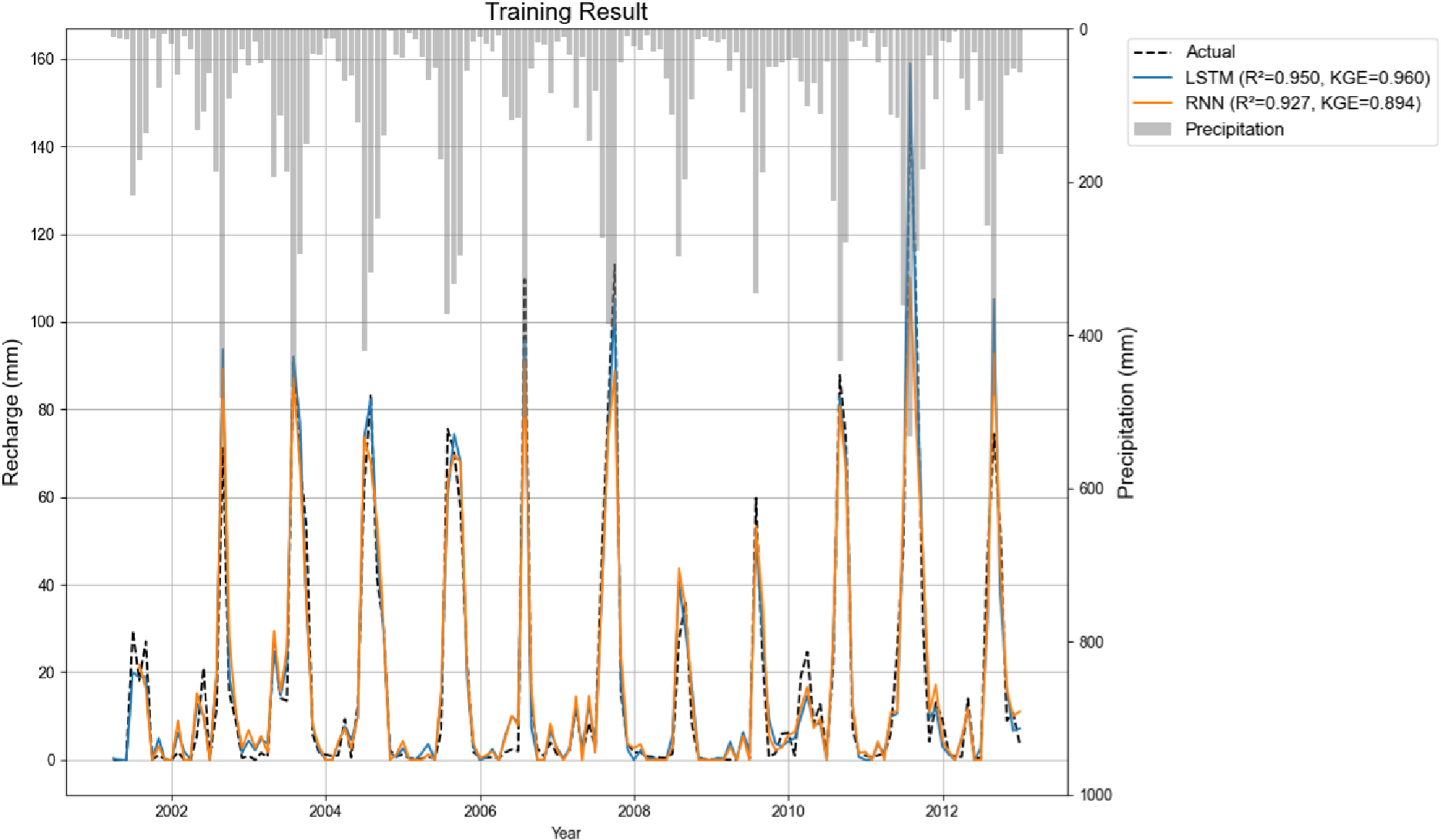
Table 4.
Performance metrics of the optimal LSTM and RNN models in the training period
| R2 | KGE | RMSE | MAE | |
| LSTM | 0.95 | 0.96 | 6.36 | 4.12 |
| RNN | 0.93 | 0.89 | 7.72 | 4.76 |
2014년 하반기부터 2015년에 걸친 극심한 가뭄 시기에는 일부 월에서 예측이 실제 함양량을 과대추정하는 경향이 나타났다. 이는 이례적으로 낮은 강수량 조건이 학습데이터에 충분히 포함되지 않아 모델이 외삽을 수행하는 과정에서 발생한 오차로 판단된다. 그럼에도 불구하고 전반적인 추세 재현 및 월별 증감 패턴 예측은 양호하였으므로, 본 모델을 향후 함양량 예측에 활용할 수 있다고 판단하였다. 다만, 가뭄 등 극단적인 낮은 함양 조건(예: 2014년 하반기–2015년)에서는 모형이 과대추정하는 경향을 보일 수 있으므로, 이를 가뭄기 운영 및 의사결정에 적용할 때에는 보수적인 해석과 추가적인 검증이 요구된다.
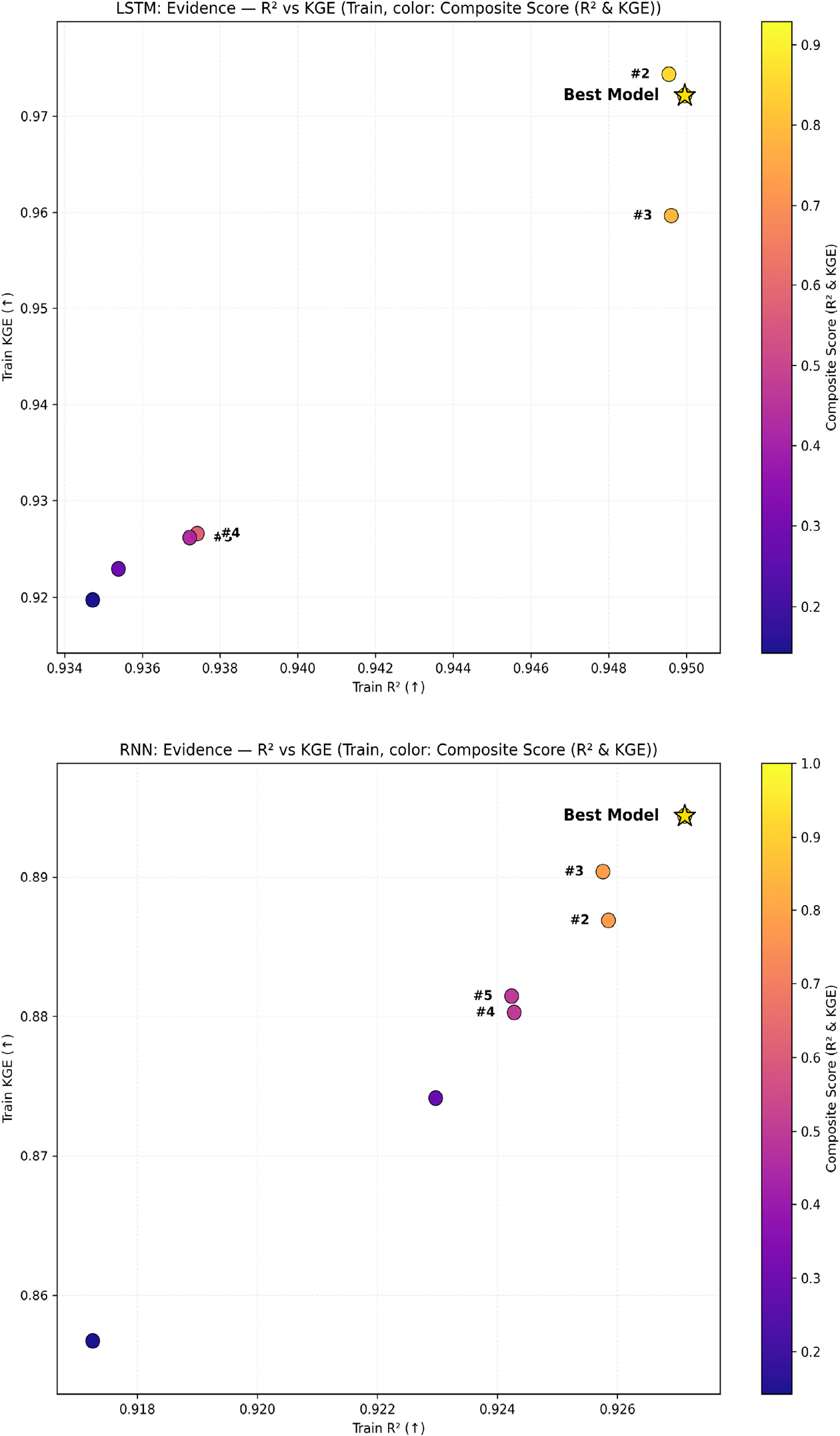
Fig. 5는 RNN과 LSTM의 후보 조합(입력 피처 조합 및 하이퍼파라미터)에 대해 학습(Train) 구간의 R2와 KGE를 동시에 제시한 결과이다. 각 점은 하나의 후보 조합을 의미하며, 색은 R2ㆍKGEㆍRMSEㆍMAE를 min-max 정규화한 뒤 가중합(가중치: KGE 0.50, R2 0.30, RMSE 0.10, MAE 0.10)으로 산정한 종합 점수(Composite score)를 나타낸다. 평가지표들의 민감도 분석을 통해 우선순위를 만든 뒤 가중치를 통해 최종 종합 평가를 수행하였다. 따라서, 단일 지표에 의존하지 않고 R2ㆍKGEㆍRMSEㆍMAE을 이용하여 종합적으로 판단하였다. 그 결과, LSTM은 RNN에 비해 높은 R2-KGE 영역에서 경쟁력 있는 후보가 상대적으로 많이 나타나, 재현성과 수문학적 일치도를 균형 있게 만족하는 조합을 확보하는 데 유리한 경향을 보였다.
2016-2023년 지하수 함양량 예측 변화
전 절에서 분석한 학습모델을 기반으로 2016년부터 2023년까지 8년간의 월별 지하수 함양량을 예측하였다. 검증구간(2013–2015)에서 관측 함양량과 LSTM/RNN 예측 함양량의 시계열 비교 및 월 강수량 변동은 Fig. 6에 제시하였다. 먼저, 모델의 일반화 성능을 확인하기 위한 검증 구간(2013–2015) 성능지표(Table 5)는 LSTM과 RNN 모두 R2 = 0.84 수준으로 나타났으며, KGE는 LSTM 0.89, RNN 0.92, RMSE는 4.39로 동일, MAE는 LSTM 3.08, RNN 2.85로 나타났다(Table 5).
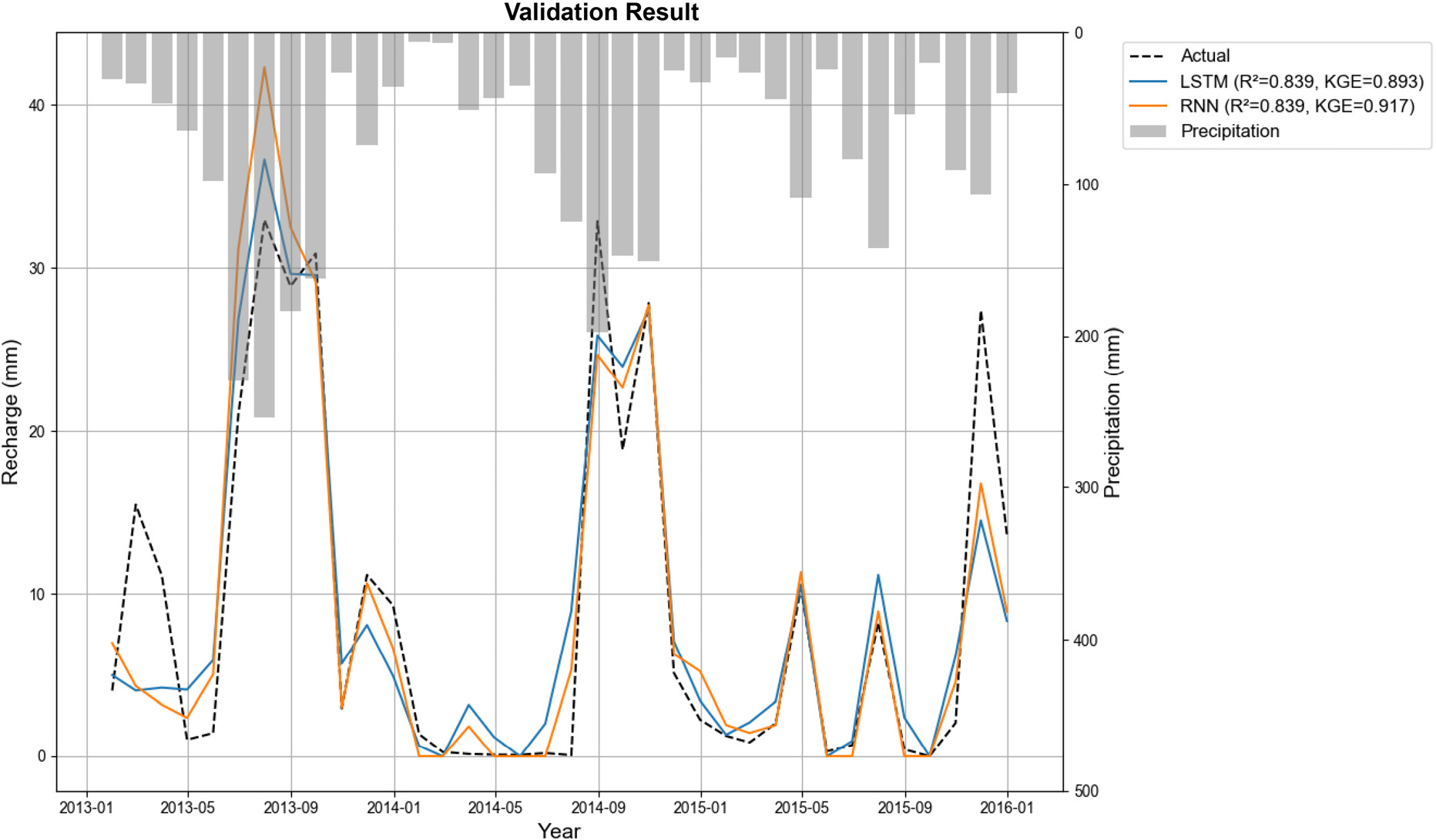
Table 5.
Performance metrics of the optimal LSTM and RNN models in the prediction period
| R2 | KGE | RMSE | MAE | |
| LSTM | 0.84 | 0.89 | 4.39 | 3.08 |
| RNN | 0.84 | 0.92 | 4.39 | 2.85 |
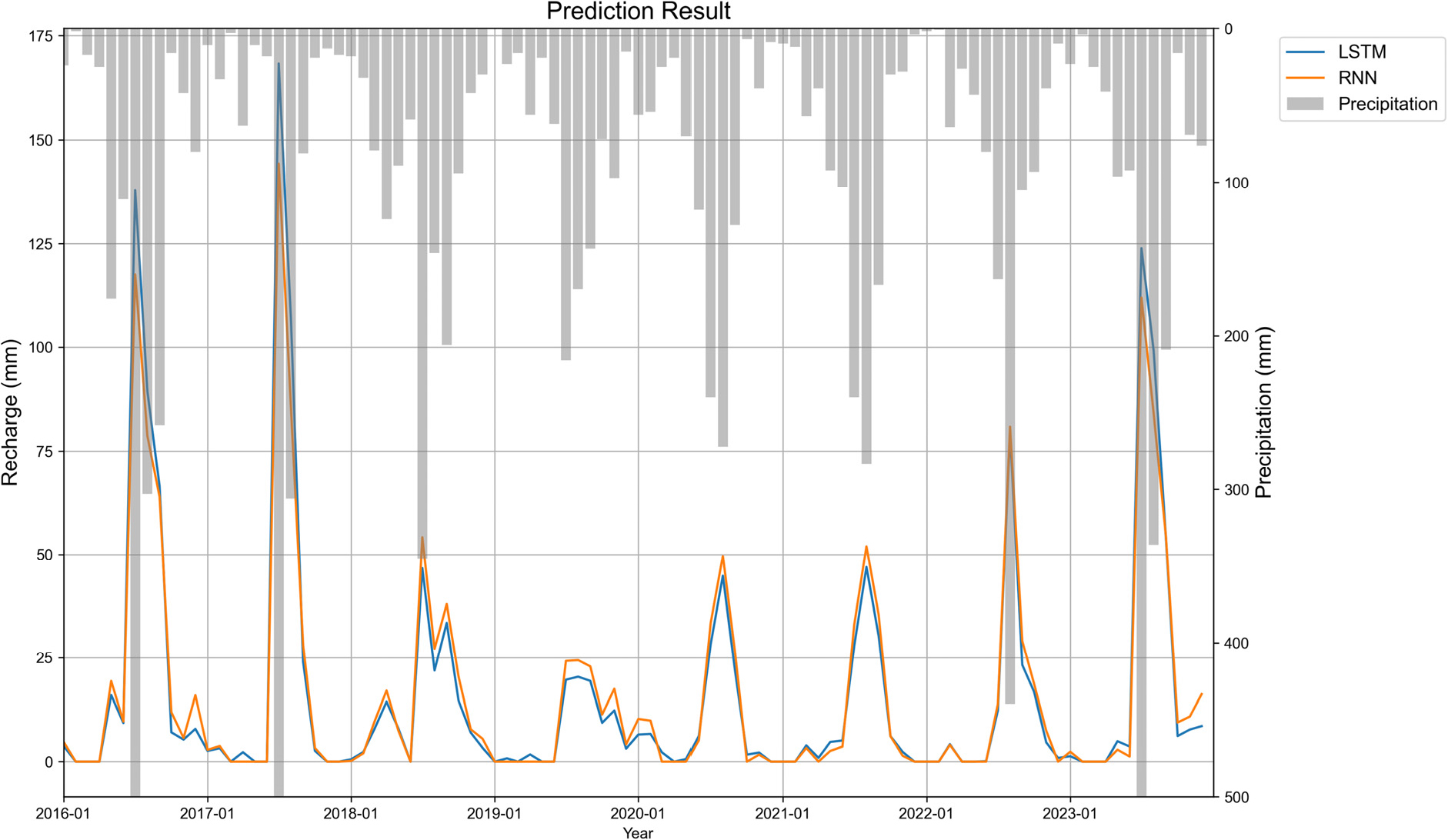
이는 강수 기반 입력만으로도 월별 함양량 변동을 실용 가능한 수준에서 재현할 수 있음을 시사하며, 이후 기간(2016–2023)으로의 예측 적용의 근거가 된다. 이러한 예측 구간 성능(R2 = 0.84, KGE = 0.89–0.92)은 지하수 함양량 예측을 다룬 선행연구에서 보고된 성능 범위와 대체로 유사한 수준이다(Table 6). 본 연구의 학습모델을 기반으로 2016년부터 2023년까지 8년간의 월별 지하수 함양량을 예측한 결과는 Fig. 7과 같다.
월별 함양량의 계절 분포를 살펴보면, 뚜렷한 계절적 패턴이 지속되었다. 과거 관측과 마찬가지로 여름철(6–8월)에 전체 함양량의 상당 부분이 집중되는 경향이 예측되었으며, 특히 7–8월 두 달 합계가 연간 함양량의 50% 이상을 차지하는 해도 있었다. 이는 장마 및 국지호우로 인한 집중강수가 함양의 주요 원동력임을 다시 한 번 확인시켜 준다. 한편 겨울철(12–2월)에는 강수량이 적고 지표면이 동결되는 등의 영향으로 함양량이 매우 낮게 예측되었다. 일부 1월이나 2월에는 월 함양량이 0에 가까운 값도 나타났는데, 이는 실제로도 동계에는 지하수 함양이 거의 발생하지 않음을 반영한 결과이다. 흥미로운 점은, 예측 결과에 나타난 어느 정도의 봄철 함양량 증가 현상이다. 3, 4월경의 함양량이 다소 올라가는 경향이 몇 년에서 발견되었는데, 이는 겨울에 대기 중 적설이 발생한 해에 봄철 해빙과 함께 지하로 침투하는 융설 효과를 모델이 포착한 것으로 보인다. 이러한 미세한 계절 변화까지도 모델 예측에 나타난 것은, 학습 데이터에 포함된 과거 사례의 패턴을 신경망이 학습한 결과라 할 수 있다. 결국, 월별 예측 결과는 과거 관측된 계절적 주기성과 강수 변동에 따른 함양 반응을 전반적으로 잘 반영하면서, 미래 시나리오에 따른 변동폭 역시 현실적인 수준으로 제시하였다.
Table 6.
Comparison of reported performance in previous studies related to groundwater recharge prediction
| Study | Target variable | Inputs | Time scale | Reported performance |
| Huang et al. (2019) |
Annual groundwater recharge (WTF-based regional estimates) |
Rainfall + meteorological predictors (e.g., wet/dry spell, rainfall days, ET, temperature) | Annual |
LSTM: R2pre = 0.70–0.84 (depending on train ratio) |
| Elsayed et al. (2020) |
Unconfined groundwater recharge |
Rainfall, temperature, sunshine hours, radiation |
Multi-year observations (≈4.5 years; 53 data points) |
ANFIS: R (testing) ≈ 0.93 (reported as correlation coefficient) |
| Wunsch et al. (2021) |
Groundwater level (as a related target variable) |
Meteorological inputs + past GWL (varies by model) |
Daily (multi-well) |
NARX / CNN / LSTM: R2 typically 0.8–0.9 (reported range) |
| Donigian (2002) |
Model performance rating guideline (HSPF applications) | - | - |
R2: Very good > 0.8; Good 0.7–0.8; Fair 0.6–0.7; Poor < 0.6 |
예측 결과의 하천 유지용수 활용 시나리오 고찰
앞서 요약한 바와 같이, 향후 기간의 지하수 함양량 예측치를 확보함으로써 무심천 유역 지하수의 하천 유지용수 활용 가능성을 평가할 수 있게 되었다. Chung et al. (2017a)이 제안한 시나리오에서는 현행 지하수 이용량(연간 약 75 mm 함양량 상당)과 최대 이용 시나리오(연간 약 290 mm 함양량 상당)를 가정하였는데, 본 연구의 예측 결과를 이와 대비하여 고찰하였다. 우선, 대부분의 예측 연도에서 연간 함양량이 75 mm를 상회하는 것으로 나타남에 따라, 현재 수준의 지하수 취수는 향후 예측기간 동안 대체로 지속 가능할 것으로 판단된다. 구체적으로, 연평균 함양량이 현 이용량과 거의 비슷하거나 그보다 많으므로, 지하수로 하천 유지용수를 공급하더라도 대수층의 장기적 고갈 위험은 크지 않을 것으로 보인다. 이는 현 수준에서의 지하수 활용은 안정적인 공급 범위 내에 있음을 시사한다. 따라서 정책적으로 현재 취수량을 유지하거나 다소 증대하는 방안(예: 취수정 추가 설치를 통한 하천 방류량 증가)을 추진할 경우, 적어도 향후 수년 간은 지하수 수지에 큰 악영향 없이 하천 건천화 방지에 효과를 거둘 수 있을 전망이다.
반면, 최대 활용 시나리오(290 mm/년 수준)와 예측 함양량을 비교하면 일부 우려사항이 도출된다. 예측 기간 중 가장 함양량이 낮게 추정된 연도의 값(약 45 mm)은 최대 활용치의 1/6 수준에 불과하며, 다수의 연도에서 함양량이 100 mm 이하로 예측되어 최대 활용 시나리오에서 가정한 취수량에 현저히 못 미친다. 이러한 결과는 이론적으로 대수층에 존재하는 풍부한 지하수를 단기간에 끌어와 하천에 공급할 수 있을지라도, 매년 그렇게 많은 양의 지하수 함양이 지속되리라는 보장은 없다는 것을 보여준다. 즉, 몇 해 연속으로 강수량이 적어 함양이 저조한 경우, 대수층에 장기간 걸쳐 함양된 저장량을 소진하면서까지 하천 유지용수를 공급해야 할 수 있는데, 이는 지속가능하지 않은 운영이 될 수 있다. 예측 결과를 종합하면, 연평균 강수량의 20% 이상을 지속적으로 함양시키는 해는 드물기 때문에, 최대 시나리오를 실행하려면 평년 이상의 강수 조건이 꾸준히 뒷받침되어야 한다. 만약 기후 변동으로 가뭄이 빈발하거나 강수 패턴의 변동성이 커진다면, 최대 시나리오의 취수량은 현실적으로 달성하기 어렵고 지하수위 급락 등의 부작용을 초래할 수 있다.
따라서 현실적인 정책 대안으로는, 가변적인 취수 전략이 필요하다. 본 예측에 따르면, 함양량이 높은 해에는 다소 지하수 취수를 늘려 하천으로 공급하되, 함양량이 극히 낮은 해에는 지하수 취수를 제한하거나 다른 수원(예: 댐 방류나 하수 재이용수)을 보완하여 사용하는 탄력적 운영이 바람직하다. 예측된 월별 함양량 자료는 이러한 세부적인 운영 전략 수립에도 활용될 수 있다. 가령, 여름철 집중 함양 이후 가을철에 비교적 지하수위가 높게 유지될 때에는 취수량을 늘리고, 겨울–초봄 함양이 거의 일어나지 않는 시기에는 취수를 최소화하는 식으로 계절별 취수 스케줄을 짤 수 있다. 딥러닝 모델은 실시간 기상 자료를 입력하여 단기 예측을 수행하는 것도 가능하므로, 향후 이를 발전시켜 운영 현장에서 월별·계절별로 취수량 가이드라인을 조정하는 의사결정 지원 시스템으로 활용할 수 있을 것이다. 이러한 접근은 통합 수문모형으로도 구현 가능하나, 딥러닝 모델은 훨씬 신속하게 계산을 수행하므로 실시간 기상 변화에 대응한 운영 시뮬레이션에 적합하다. 예를 들어, 예상치 못한 가뭄 경보가 발령되면 즉각적으로 향후 수개월의 함양량을 예측하고 취수 계획을 재조정하는 등 운영상의 기민성을 확보할 수 있다.
또 다른 측면에서, 본 연구의 예측 모형은 물리적 요인들을 명시적으로 고려하지 않기 때문에 결과 해석 시 주의가 필요하다. 예측된 함양량 변화가 어떠한 구체적 인과관계에서 비롯되었는지는 딥러닝 모형 자체로는 설명하기 어렵다. 예컨대, 토양포화도, 증발산, 지하수위 변동 등 함양에 영향을 주는 내부 과정을 모델이 명시적으로 출력하지 않으므로, 이러한 상세 분석은 여전히 통합 수문모델 등의 역할로 남겨져 있다. 따라서 딥러닝 모형은 정책 수립 초기 단계에서 신속한 시나리오 평가를 위한 도구로 활용하고, 최종적인 세부 운영 계획 수립이나 영향 평가 단계에서는 물리기반 모델링을 병행하여 사용하는 복합적 접근이 이상적일 것이다. 예측 결과에 나타난 함양량의 절대치는 통합모형 결과와도 교차 검증해볼 필요가 있으며, 두 접근의 차이가 큰 경우 그 원인을 분석하여 모델을 개선해야 한다. 다행히도, 본 연구에서 제시한 예측 모델은 기존 물리모델의 결과와 비교적 잘 부합하는 경향을 보였고, 중요한 변동 패턴도 일치함을 확인하였다. 이는 충분한 관측 데이터가 확보된다면 딥러닝 모델이 물리기반 모형을 보완적으로 활용할 수 있는 가능성을 보여준다.
결론 및 토의
본 연구에서는 딥러닝 기법을 활용한 무심천 유역의 지하수 함양량 장기 예측 모델을 개발하고, 2016년부터 2023년까지 8년간의 월별 함양량을 예측함으로써 지하수 기반 하천 유지용수 공급 전략에 필요한 과학적 근거를 제공하였다. 주요 결론 및 시사점을 정리하면 다음과 같다.
(1) 무심천 유역에서 지하수를 가뭄시 하천 유지용수로 활용하는 방안이 제시된 바 있으며, 이를 실행에 옮기기 위해서는 향후 수문조건 변화에 따른 지하수 함양량의 변화 추이를 미리 예측하는 작업이 필수적임을 확인하였다. 본 연구는 이러한 요구에 부응하여 딥러닝 기반 예측모형을 구축하고, 2016년부터 2023년까지의 함양량 변화를 전망함으로써 정책 수립에 필요한 선행 정보를 제공하였다.
(2) 개발된 인공신경망 모델은 강수량 자료만으로 과거 함양량의 패턴을 학습하였으며, 검증기간 동안 양호한 예측 성능을 보였다. 이를 바탕으로 미래 강수 시나리오를 입력하자 즉각적으로 함양량 예측값을 산출해내는 높은 계산 효율을 확인하였다. 이는 전통적인 SWAT-MODFLOW 통합모델과 비교할 때 속도 측면의 장점이 크다는 것을 의미하며, 모형 구축 및 실행에 걸리는 노력을 크게 절약할 수 있었다. 따라서 본 딥러닝 모형은 정책 수립 초기 단계에서 다양한 시나리오를 신속히 평가하고 의사결정에 활용할 수 있는 예측 도구로서의 잠재력을 보여주었다.
(3) 예측된 2016–2023년 함양량은 대체로 과거 수준과 유사하거나 다소 증가하는 경향을 보였으나, 강수량 변동에 따라 연간 함양량의 등락 폭이 크게 나타났다. 대부분의 해에는 현재 지하수 이용 수준을 충족할 만한 함양이 기대되지만, 가뭄이 심한 해에는 함양량이 급감하여 과도한 지하수 취수가 어려울 수 있다. 따라서 지하수 이용의 지속가능성을 확보하기 위해서는 강수 조건에 따라 취수량을 탄력적으로 조절하고, 함양이 풍부한 시기에는 저장을 확대하는 등 예측 정보를 기반으로 한 능동적 운영 전략이 필요하다.
(4) 본 연구의 접근법과 결과는 특정 유역에만 국한되지 않고, 자료가 확보되는 다른 지역에도 확장 적용될 가능성을 지닌다. 선행 연구(Chung et al., 2017b)의 제주도 사례와 비교하면, 서로 다른 지형·기후 조건에서도 딥러닝 기반 예측이 월 단위 변동성을 재현할 수 있다는 점에서 공통점이 확인된다. 다만 지역별 강수-함양 반응 특성과 관측 자료의 품질이 예측 성능을 좌우할 수 있으므로, 적용 시에는 입력 자료의 일관성 확보와 지역 특성에 맞춘 재학습이 필요하다. 향후 유역별 동일 절차를 병렬로 적용한다면, 장시간이 소요되는 전국 규모 물리모형 시뮬레이션을 보완하는 형태로 ‘지역별 빠른 예측’ 체계를 구축할 수 있을 것으로 기대된다.
(5) 딥러닝 기반 수문 예측모델의 신뢰성과 활용도를 높이기 위해서는 후속 연구가 필요하다. 첫째, 물리적 해석력을 높이기 위해 LSTM 계열 시계열 모형뿐 아니라 공간 상관성을 반영할 수 있는 Graph Neural Network 등 최신 알고리즘의 적용을 검토할 수 있다. 둘째, 앙상블 예측과 불확실성 정량화가 요구된다. 여러 모형의 예측을 종합하거나 Monte Carlo dropout 등을 활용해 오차 범위를 제시하면, 의사결정자가 보다 안전하게 계획을 수립할 수 있다. 셋째, 기후변화 시나리오(RCP/SSP)와의 연계를 통해 2030년 이후 함양량 변화를 전망하면 장기 적응 전략 수립에 유용한 근거가 될 것이다. 넷째, 물리기반 모형과의 하이브리드 통합을 통해 상호 보완적 장점을 극대화할 수 있다. 예를 들어 딥러닝 예측값을 물리모형의 경계조건/초기조건으로 활용하거나, 물리모형 출력(예: 수위 분포)을 딥러닝으로 보정하는 방식이 가능하다.
