서 론
연구지역 및 이용 자료
방법론
지하수위 예측 모델
최종 예측 모델개발 방법
결과 및 논의
Test Case 1에 대한 성능 검증 결과
Test Case 2에 대한 성능 검증 결과
최종 예측 모델을 통한 중제주 수역 성능 검증 결과
결 론
서 론
지하수는 중요한 담수 공급원 중 하나이며, 지표수에 비해 기상변화로 인한 영향을 적게 받는다(Custodio, 2000; Giordano, 2009; Famiglietti, 2014). 이러한 이유로 기후변화에 의한 가뭄의 발생 빈도가 높아짐에 따라 보다 안전한 수자원 확보의 가치가 중요해지면서 지하수의 역할에 대한 중요성이 점점 증가하고 있다(Giordano, 2009; Siebert et al., 2010; Taylor et al., 2013). 그러나 지하수는 대수층 시스템이 한번 악화될 경우, 이의 양적 및 질적 복구에는 일반적으로 오랜 시간이 걸린다. 따라서 대수층 시스템의 건전성에 대한 지속적인 모니터링과 효율적인 관리가 반드시 필요하다.
연구지역인 제주도는 연평균 강수량이 1,963 mm로 육지의 연평균 강수량인 1,316 mm에 비하여 상당히 많은 다우지역임에도 불구하고 투수성이 높은 제주도의 지질특성(단열, 클링커층, 용암터널 등)에 의하여 지역의 하천이 대부분 건천으로 발달하고 하천을 통한 유출이 상대적으로 짧은 기간에 발생하여 지표수를 수자원으로 활용하기 어렵다(Yang, 2007; Jung and Yang, 2009; Kim, 2021). 이에 따라, 제주도는 이용되는 총 담수량의 81% 이상을 지하수에 의존하고 있는 실정이다(Kim et al., 2003; Jeju Province, 2018). 최근 상주인구가 지속해서 유입되고 관광객이 증가함에 따라 제주도의 지하수자원의 양적 저하량은 해마다 증가하고 있으므로(Jeong et al., 2022), 제주지역의 지속 가능한 지하수자원 활용을 위한 체계적인 지하수량 관리 방안 마련이 필요하다.
지하수량의 건전성을 지속적으로 관리하기 위해서는 지하수위를 정확하게 예측하고 이를 실제 관측자료와 실시간으로 비교함으로써 대수층 시스템의 이상을 감지할 수 있어야 한다. 이뿐만 아니라, 미래 지하수위 예측 정보는 미래 지하수량 관리를 위한 적정 지하수 이용량을 산정하는 데 활용할 수 있어야 한다. 최근에는 다양한 외부 요인을 고려하여 지하수위 예측의 정확도를 높이기 위하여 자료 기반 수학적 모델(data-driven model)을 이용한 연구들이 점점 증가하는 추세이다(Maier and Dandy, 1996; Coulibaly et al., 2001; Altunkaynak, 2007; Chang et al., 2014; Young et al., 2015; Liu et al., 2018; Wunsch et al., 2018). 지하수위 예측에 이용되는 자료 기반 모델로 인공신경망(artificial neural network), 비선형 자기회귀외인 모델(non-linear auto-regressive exogenous model), 회귀 신경망(recurrent neural network) 등이 이용되고 있다(Coulibaly et al., 2001; Chang et al., 2014; Kenda et al., 2018; Wunsch et al., 2018; Zhang et al., 2018; Jeong and Park, 2019).
그러나 대부분의 기존 연구들에서는 강수량과 같은 기상학적 요인들만을 고려하여 지하수위를 예측하였다. 반면, 지하수위는 지하수 이용에 의해서도 많은 영향을 받기 때문에 실제 지하수위를 표현하기 위해서는 자연적 요인인 기상자료뿐만 아니라 인위적 요인인 지하수 이용량까지 입력자료로 활용하여 관계 모델을 개발하는 것이 반드시 필요하다. 지하수 이용량과 기상자료를 모두 입력인자로 활용하여 지하수위 예측 모델을 개발할 경우, 이를 기반으로 신고되지 않은 초과 지하수 이용에 대한 지속적인 감시를 수행할 수 있다. 또한, 미래 기상 시나리오 대비 적정 지하수 이용량을 산정하는 데 개발된 모델을 활용할 수 있다(Lee et al., 2021).
본 연구에서는 제주도 중제주수역의 총 12개의 지하수 관측정에서의 미래 지하수위를 예측하기 위한 모델을 개발하였다. 예측 모델개발을 위해 강수량 및 지하수 이용량 자료를 활용하였으며, 예측 모델의 성능을 향상시키기 위한 다양한 방안을 고안 및 비교 검증하여 최종 예측 모델을 제시하였다. 개발된 모델은 중제주 수역의 지하수량 변화를 실시간으로 감시하고 미래 적정 지하수 이용량을 제시하기 위한 정보로 활용될 수 있을 것이다.
연구지역 및 이용 자료
본 연구에는 일 단위 강수량, 지하수위 변동 및 이용량 시계열 자료가 이용되었으며, 개발되는 모델의 성능 검증을 위해서는 가능한 많은 자료가 필요하다. 획득된 자료 중에서 중제주 수역 내 지하수 이용량 자료를 가장 많이 확보하여, 2001년부터 2022년까지 중제주 수역에 걸쳐 분포하는 관측공으로부터 획득한 자료를 이용하였다. 강수량 자료는 총 3개의 관측소(제주, 오등, 및 삼각봉)에서 획득하였고, 이용량 자료는 총 413개 지점, 그리고 지하수위는 총 12개 지점(JI오등1, JI오등2, JI오등4, JI오등5, JD용담1, JM도남2, JM이도2, JP오라, JW공항, JW연동, JW일도, 금산수원지)에서 획득하였다. 이들 관측 지점의 분포는 Fig. 1에 나타나 있다. 지하수위 관측 지점은 초록색, 강수량 관측지점은 파란색, 그리고 지하수 이용량 관측 지점은 붉은색 점으로 표시되었다. 획득된 강수량, 지하수 이용량 및 지하수위 시계열 자료는 모두 일 단위로 확보되었으며, 본 연구에서는 일 단위 강수량 및 지하수 이용량과 과거 지하수위 자료를 기반으로 미래의 일 단위 지하수위를 특정 기간으로 예측할 수 있는 모델을 개발하였다.

방법론
지하수위 예측 모델
누적 장단기메모리(stacked long short-term memory)
본 연구는 지하수위 예측을 위해 누적 장단기메모리(stacked-LSTM)를 이용하였다. Stacked LSTM을 설명하기 앞서, LSTM은 회귀신경망(recurrent neural network)의 일종으로 은닉층의 정보가 예측을 위한 입력정보로 활용됨에 따라 시계열 자료의 과거 변동 패턴을 예측에 활용하는데 효과적인 것으로 알려져 있다(Hochreiter and Schmidhuber, 1997; Zhang et al., 2018). 이러한 장점 때문에 기상자료 시계열 자료를 기반으로 지하수위의 장기적 변동 패턴을 학습하는 데 많이 이용되고 있다(Jeong and Park, 2019; Afzaal et al., 2020; Müller et al., 2021). Fig. 2a는 LSTM의 일반적인 예측 네트워크에서 보는 바와 같이 과거의 은닉 정보 및 입력자료가 현재의 예측에 지속적으로 영향을 주는 네트워크를 가지고 있다. 지속적인 과거 정보 입력을 기반한 LSTM 네트워크 학습 시 예측 가중치의 소실(vanishing) 및 폭주(exploding) 문제를 해결하기 위하여 불필요한 입력의 기억을 지우기 위한 입력(input), 망각(forget), 및 출력(output) 게이트(gate)가 존재하며 이들을 합쳐 LSTM cell이라 칭한다. 본 연구에서는 보다 비선형 지하수위 예측모델을 개발하고자 하였으며, 이를 위해 LSTM cell을 여러 층으로 쌓는 학습 네트워크인 stacked-LSTM을 최종적으로 이용하였다(Fig. 2b).

순차의 총 개 종류의 입력변수(, )와 순차의 지하수위가 주어졌을 때(), stacked-LSTM을 이용한 시간부터 총 기간 동안의 지하수위()는 다음과 같이 예측된다.
위 식에서 , , 및 는 시간에 대한 번째 LSTM cell, cell 연산을 위한 입력, 출력, 및 망각 게이트를 의미하며, 입력, 출력, 및 망각 게이트의 차원은 은닉 뉴런을 의미하는 와 동일하다. 그리고 는 입력으로 이용되는 변수의 순차 길이를 의미한다. 기호 는 원소곱을 의미하고, 는 활성 함수를 의미하며 이에는 hyperbolic tangent 함수, sigmoid 함수, rectified linear unit 등이 이용될 수 있다.
개발된 예측 모델 성능 검증 지표
본 연구에서 개발하고자 하는 지하수위 시계열 예측 모델은 회귀모델임에 따라 해당 모델 예측 결과에 대한 성능평가는 예측 지하수위와 실제 지하수위 간 상관계수(correlation coefficient, ρ) 및 root mean square error(RMSE)를 이용하였으며, 두 식은 아래와 같이 계산된다.
위 식에서 는 번째 실제 지하수위를 의미하며 는 검증용 지하수위 자료의 평균을 의미하고, 는 번째 예측 지하수위, 는 검증용 지하수위에 대한 예측값의 평균을 의미한다.
최종 예측 모델개발 방법
본 연구에서는 stacked LSTM 모델을 기반으로 과거 시점에서 관측된 강수량 및 지하수 이용량을 기반으로 미래 한 달간의 지하수위를 예측하고자 하였다. 따라서 예측모델의 입력자료로 강수량, 지하수 이용량 및 지하수위 자료가 활용되었다. 이때, 특정 기간의 과거 강수량 자료를 입력자료로 활용하는 데 있어, 활용되는 과거 강수량 자료의 기간에 따라 예측 모델의 성능이 달라질 수 있다. 이뿐만 아니라 연구지역 내에서 확보된 지하수 이용량을 관측한 관정의 개수가 상당히 많고, 이를 모두 이용하였을 때, 모델의 예측성능이 충분하지 않음에 따라, 지하수위 예측에 활용할 지하수 이용량 관정에 대한 선별작업이 필요하였다. 따라서 본 연구에서는 관정별 최적의 지하수위 예측 모델개발을 위해 이용되는 입력자료로 변화에 의한 모델 네트워크 변화에 따른 성능 검증이 실시되었으며, 이를 통해 12개의 관측정에 최종으로 적용될 최적의 모델 네트워크를 선정하였다.
최종 모델개발을 위해 적용된 연구 과정은 Fig. 3과 같다. 그림에서 보는 바와 같이 최종 모델개발을 위해 먼저, 확보된 자료에 대한 다양한 전처리를 수행하였다. 전처리를 위해 이상치와 결측치는 분석에서 제외하였으며, 이들을 제외하고 공통으로 확보 가능한 시계열 기간에 대하여 지하수위, 강수량, 및 지하수 이용량 자료를 확보하여 학습용 및 검증용 자료로 구축하였다. 그리고 예측 모델에 대한 하이퍼파라미터(stacked-LSTM cell 개수, 활성함수 등)를 베이지안 최적화(Bayesian optimization, Snoek et al., 2012)를 통해 결정하여 미래 지하수위 예측을 위한 예비 모델을 구축하였다. 이때, 예비 모델은 30일 후를 예측하는 모델로 구축되어 성능이 평가되었다. 예비 모델 구축에는 여러 가지 테스트 케이스가 고려되었으며, 이들의 성능을 비교 검증하여 가장 우수한 예측성능을 보이는 모델을 최종 지하수위 예측 네트워크로 결정하였다. 성능 검증을 위해 비교된 모델 네트워크의 종류는 다음과 같다.
1) Test Case 1: 입력으로 이용되는 자료 종류의 개수에 따른 모델 성능 비교
• (Model 1-1) 입력자료로 과거 강수량, 주변 50개 관정으로부터 획득한 과거 지하수 이용량, 및 과거 지하수위를 사용하는 모델
• (Model 1-2) 입력자료로 과거 강수량, 민감도분석을 통해 선별된 관정의 과거 지하수 이용량, 및 과거 지하수위를 사용하는 모델
• (Model 1-3) 입력자료로 과거 강수량 및 민감도분석을 통해 선별된 관정의 과거 지하수 이용량을 사용하는 모델
2) Test Case 2: 입력으로 이용되는 과거 순차 자료의 길이에 따른 모델 성능 비교
• (Model 2-1) 과거 120일의 순차 자료를 입력자료로 사용하는 모델
• (Model 2-2) 과거 60일의 순차 자료를 입력자료로 사용하는 모델
• (Model 2-3) 과거 30일의 순차 자료를 입력자료로 사용하는 모델

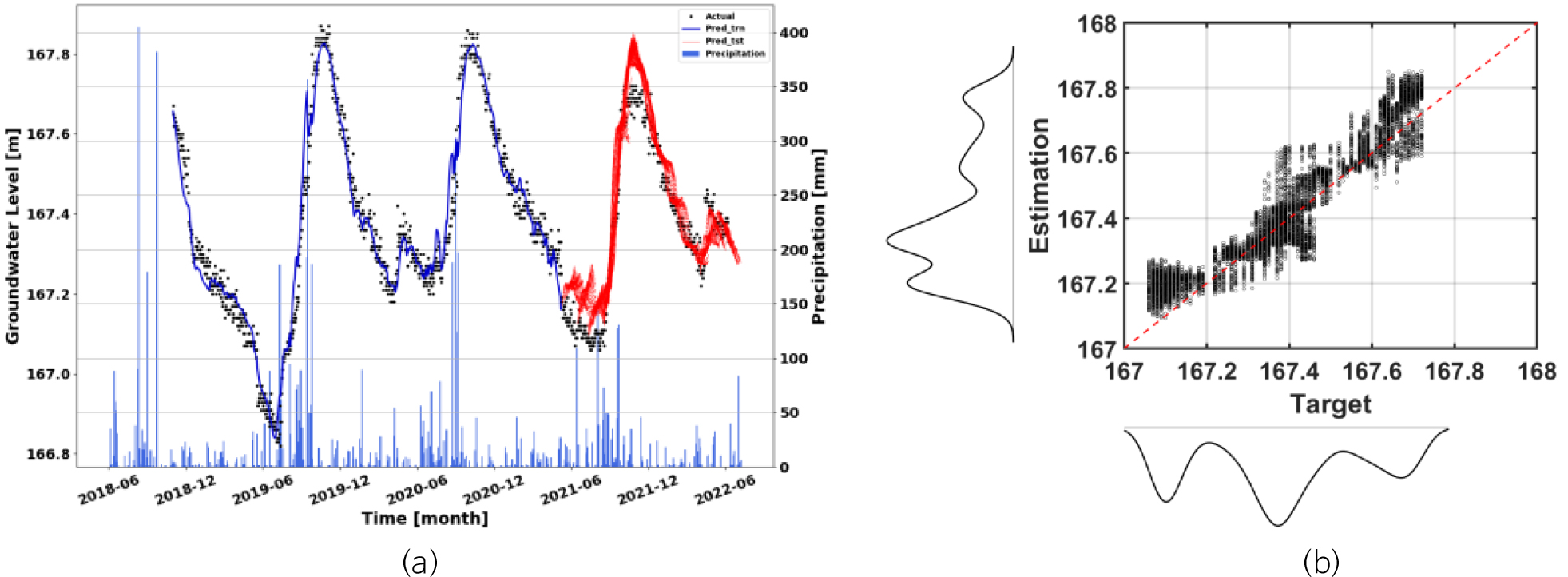
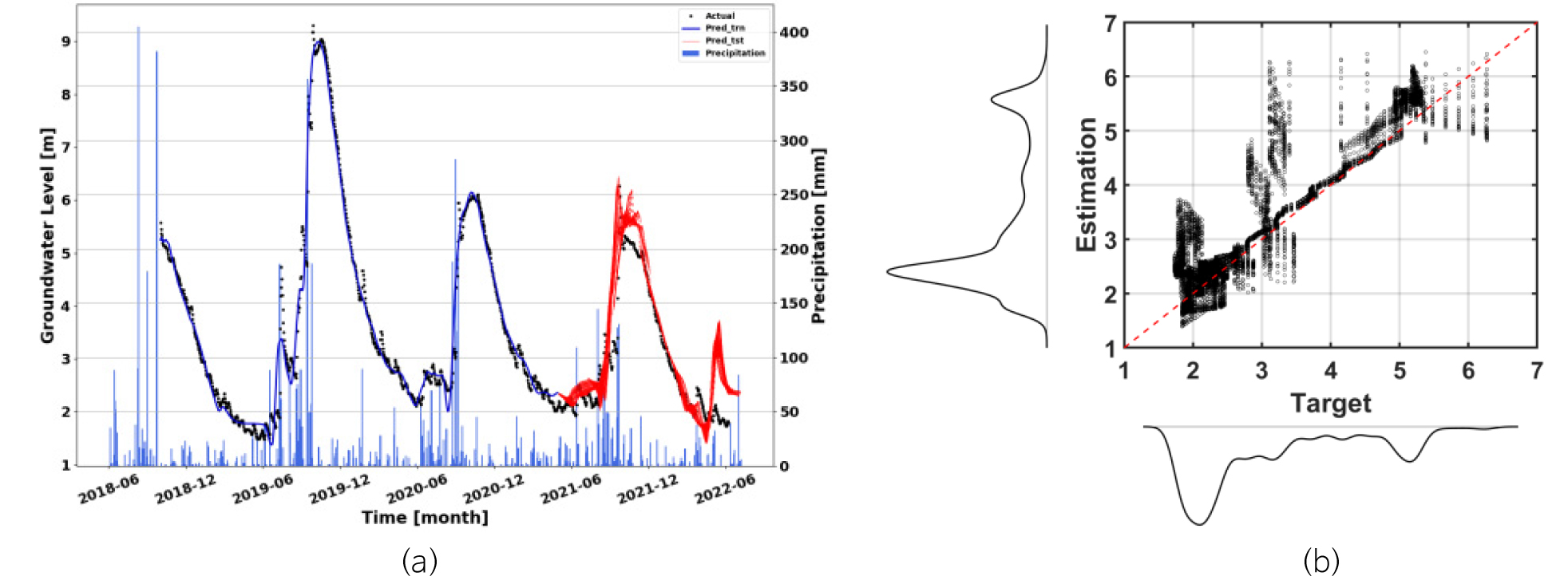
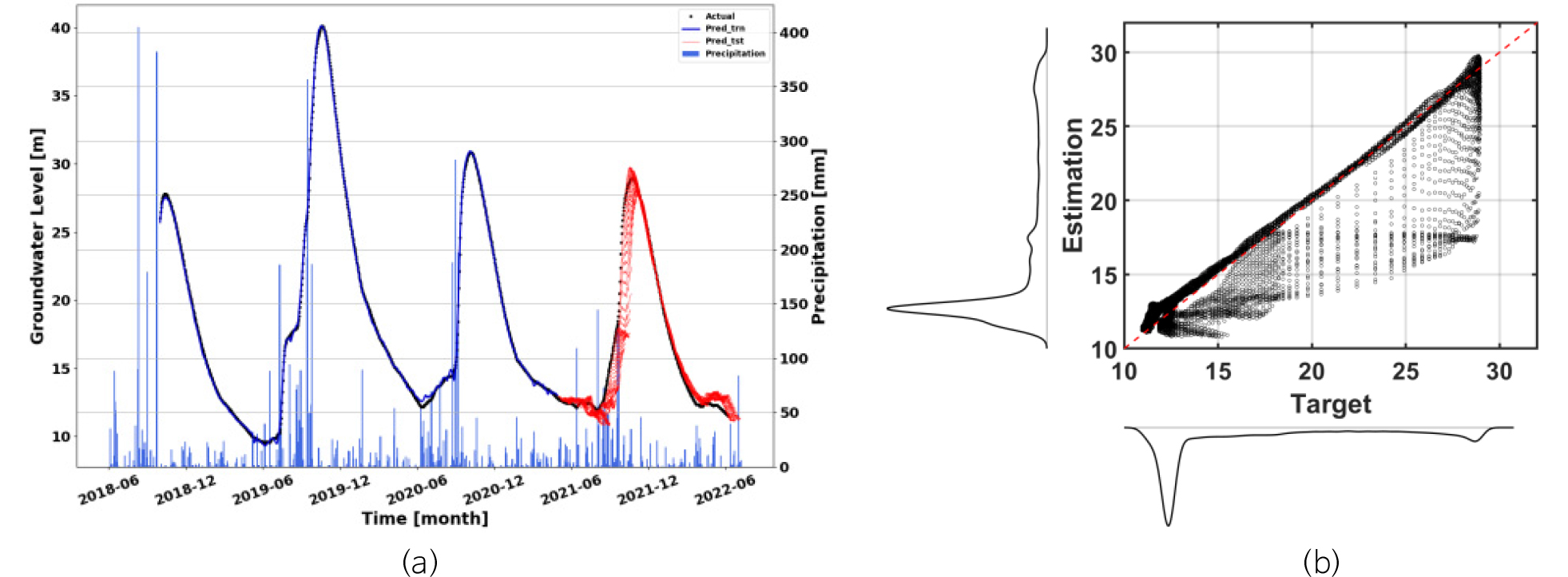
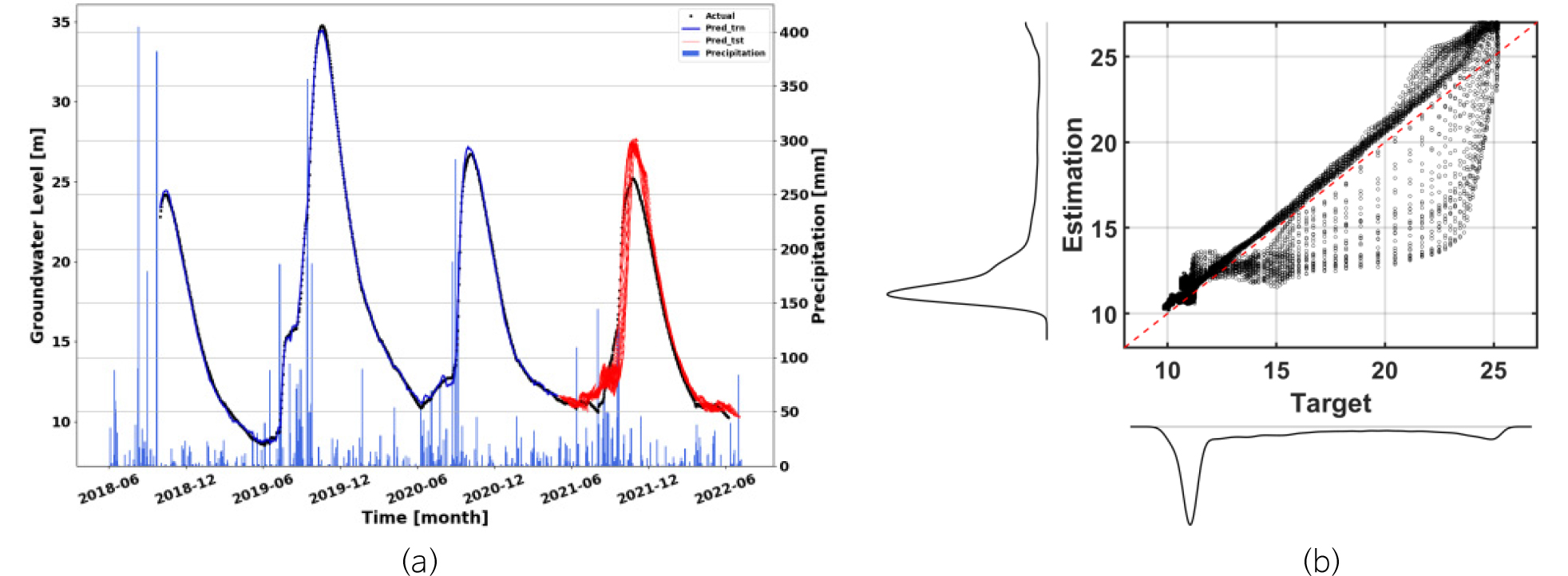
다양한 성능 비교 검증을 통해 구축된 최종 모델의 네트워크를 기반으로 미래 30일 동안의 지하수위를 예측할 수 있는 모델을 최종적으로 개발하였으며, 해당 모델이 각 관정의 미래 지하수위를 예측하는 데 최종 이용되었다. 다만, 관정별 이용하는 과거 순차 자료의 길이는 모두 다른 길이를 기준으로 검증을 수행 및 최종 모델이 도출되었다. 본 연구에서는 JI오등1 관정에 대하여 해당 프로세스를 적용한 결과를 구체적으로 기술하였으며, 나머지 관정에 대하여 최종 개발된 예측 모델의 성능은 부록으로 제시하였다(Appendix A).
본 연구에서 이용된 민감도분석 기법으로 섭동 민감도분석(perturbation sensitivity analysis) 기법이 이용되었으며(Castillo et al., 2006; Prabhakaran et al., 2019), 이는 예측 모델 구축 후, 입력으로 이용되는 자료에 임의값을 입력한 후, 출력 결과의 변화량을 평가하는 기법이다. 출력의 변화량이 클수록 해당되는 입력 인자의 민감도가 높음을 의미한다. 본 연구에서는 입력값으로 이용되는 50개 위치의 지하수 이용량 관측값을 하나씩 변화시키면서 지하수위 예측 결과의 성능 저하량을 측정함으로써 각 이용 관정이 지하수위 관측지점에 미치는 영향력을 평가하였다.
결과 및 논의
본 연구에서 개발된 모델을 이용하여 예측된 지하수위 예시는 Fig. 4와 같다. 그림에서 파란색 막대그래프는 강수량, 검은색 점은 실측 지하수위, 붉은색 실선은 예측 모델을 이용한 예측 지하수위를 의미한다. 검증용 자료에 대한 결과이며, 각 예측 시점을 기준으로 30일 기간의 미래 지하수위를 예측함에 따라 각 시점마다 여러 개의 예측 지하수위 결과들이 중첩되어 나타나 있다. 본 연구에서는 정량적 예측 성능지표를 계산하기 위하여, 예측 마지막 날짜인 30일 후의 예측 결과를 이용하였다.

Test Case 1에 대한 성능 검증 결과
Case 1에서는 지하수위 예측을 위해 이용되는 과거 자료의 순차 길이는 모든 테스트 모델에 대하여 고정 후 입력 데이터의 종류를 변화시키며 성능 검증을 수행하였다. Fig. 5 및 Fig. 6은 구축된 3가지 모델의 지하수위 예측 결과 및 예측값과 실측값 간의 산점도를 보여준다. Fig. 5에서 검은색 점은 실제 지하수위를 의미하며, 파란색 및 붉은색 실선은 각각 학습용 및 검증용 자료에 대한 예측 지하수위를 의미하고, 파란색 막대그래프는 가장 근거리에 위치한 강수 관측소에서 측정된 강수량 자료를 의미한다. Fig. 6은 실측 지하수위(x-축)와 예측 지하수위(y-축) 간의 산점도로 붉은색 점선인 1:1 선에 산점도가 가까이 분포할수록 두 값이 유사함을 나타낸다. 그림에서 보는 바와 같이 검증용 자료에 대하여 Model 1-2인 모든 자료를 모두 입력자료로 활용하면서 선별된 관측정에서의 지하수 이용량 자료만을 입력으로 활용한 모델이 가장 실제 지하수위를 유사하게 예측하는 것을 확인할 수 있다. 산점도 그림에서도 Model 1-2를 활용하는 경우가 1:1 대응 라인 근처에 값들이 도시되는 것을 확인할 수 있다. 한편, Fig. 5c와 같이 과거 지하수위를 이용하지 않을 때 지하수위 상승 및 하강 시점을 예측하는 데 어려움이 존재하는 것으로 보이며, 지하수 이용량을 선별없이 활용하는 경우, 입력인자의 차원이 증가함에 따라 예측 모델의 성능이 이에 대한 부정적 영향을 받는 것으로 확인되었다.


정량적 성능 비교 결과 또한 모든 종류의 입력자료를 활용하는 모델이 가장 우수한 성능을 보여주고 있다(Table 1). Model 1-2의 예측 지하수위와 실제 지하수위 간의 RMSE는 0.9939 m로 타 모델(Model 1-1: 1.5702 m; Model 1-3: 1.9349 m) 보다 현저히 낮으며, 두 자료 간 상관계수 또한 Model 1-2가 0.9549로 Model 1-1 및 Model 1-3이 0.8009 및 0.8569를 보이는 것에 비해 높게 나타난다. 이를 통해, 예측 모델의 입력변수로 다양한 종류의 자료를 활용하되 민감도가 높은(즉, 관련성이 높은) 자료를 입력자료로 활용하는 것이 예측 모델의 성능 향상에 도움이 됨을 확인할 수 있다.
Table 1.
Quantitative performances of the three types of model for predicting groundwater level in test Case 1
| RMSE (m) | ρ | |
| Model 1-1 | 1.5702 | 0.8009 |
| Model 1-2 | 0.9939 | 0.9549 |
| Model 1-3 | 1.9349 | 0.8569 |
Test Case 2에 대한 성능 검증 결과
제주지역은 해발 약 2,000의 높은 한라산이 중심에 위치하는 지형학적 조건으로 인하여 일반적으로 중산간 지역에 강수가 집중 및 함양된 후, 해안지역 방향으로 지하수 유동이 발생한다(Won et al., 2006; Kim and Yang, 2019). 특히, 제주지역과 같이 높은 투수성을 가진 지역에서도 불포화대가 두꺼운 지역에서는 지하수의 지연시간(delay time)이 한 달을 초과하기도 한다(Park et al., 2021). 이로 인해 중산간 아래에 위치하는 중제주 수역 내 지하수위의 변동과 강수 시점 간의 지연시간이 발생할 수 있고, 특히 제주 중산간 지역의 지하수위는 상당히 깊은 심도에 위치함에 따라 강수 발생 후 침투수가 지하수면으로 함양될 때까지 더욱 긴 지연시간이 발생할 수 있다(Kim et al., 2014; Shin et al., 2014, 2020). 따라서 제주지역의 지하수위를 예측하기 위해서는 과거의 강수량 순차 자료가 충분히 반영되는 것이 예측성능 향상에 유리할 수 있고, 본 연구에서는 이러한 제주지역의 지형학적 특징을 모델에 반영하기 위하여 stack-LSTM 모델의 입력자료로 활용되는 순차 자료의 길이를 조절하여 성능을 비교 검증하였다.
Case 1에서 강수량, 지하수 이용량 및 과거 지하수위를 모두 입력자료로 활용하는 것이 예측성능 향상에 도움이 된다는 결과를 확인함에 따라 Case 2에서는 Case 1에서 활용한 입력자료를 활용하되, 입력으로 이용되는 과거 순차 자료의 길이에 따라 모델 네트워크를 달리하여 Case 2의 모델을 구축 및 성능 비교를 실시하였다. Case 1에 해당하는 3가지 모델은 공통적으로 영향력이 큰 10개의 지하수 이용량 관정에서 지하수 이용량 자료를 입력자료로 이용하며, 강수량 정보 또한 동일한 자료가 모델에 적용되었다. Figs. 7, 8 및 Table 2는 3가지 모델 예측 결과 및 예측값과 실측값 간의 산점도와 이의 정량적 성능을 보여준다. 두 그림과 표에서 보는 바와 같이 입력으로 이용되는 자료의 길이가 증가할수록 실측 및 예측 지하수위 간 차이가 감소하여 RMSE가 낮아지고 ρ 값이 증가하는 것을 확인할 수 있다. 이는 제주지역의 강수량과 지하수위 변동 간 지연시간이 상당히 길게 존재함을 의미하며, 이는 중산간 지역의 지하수위 심도가 깊은 심도에 위치하기 때문으로 판단된다. 따라서 본 연구에서는 JI오등1 관정에 대하여 과거 120일의 강수량, 지하수 이용량 및 지하수위를 입력자료로 하는 모델 네트워크를 최종 예측 모델로 결정하였다.
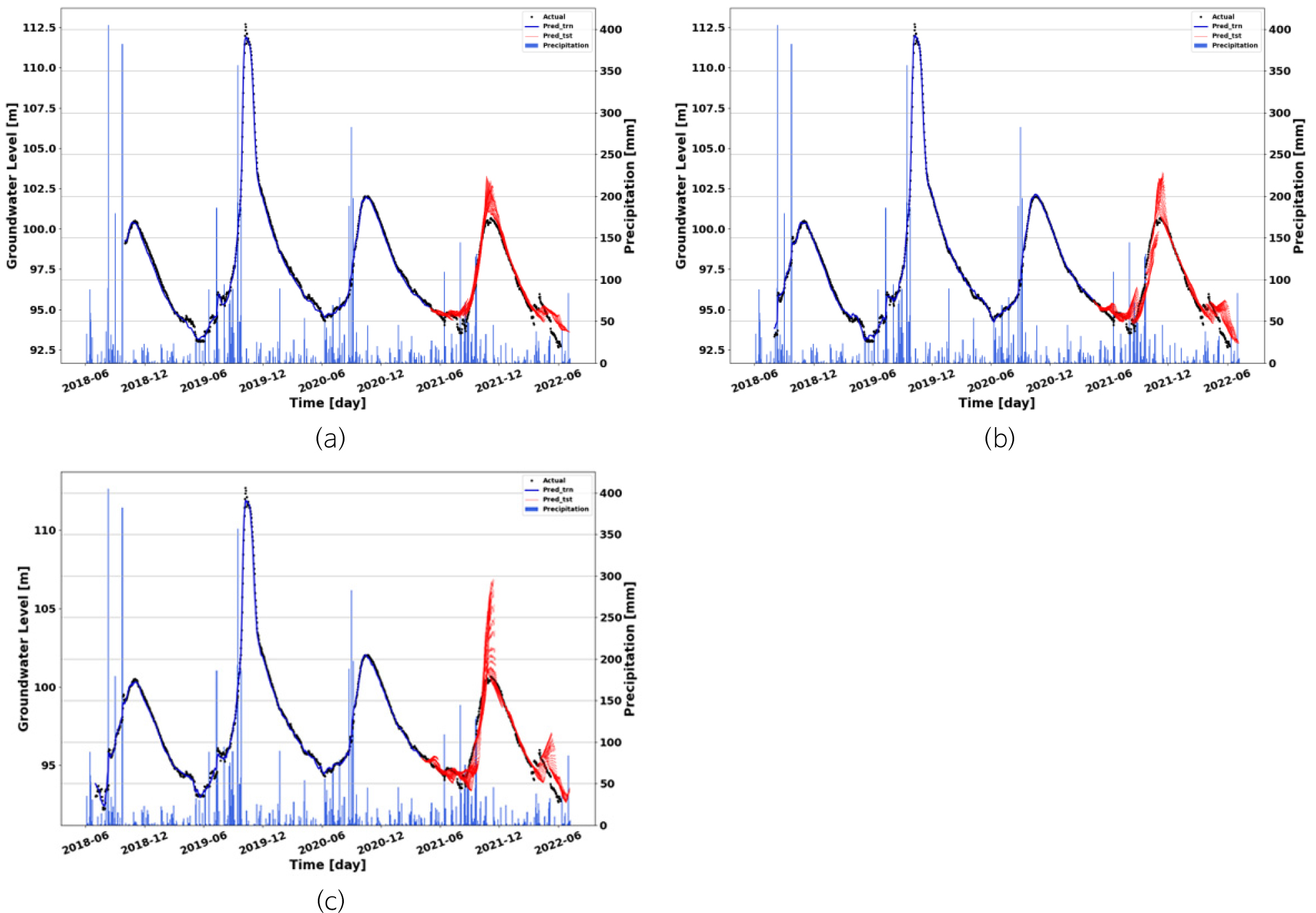
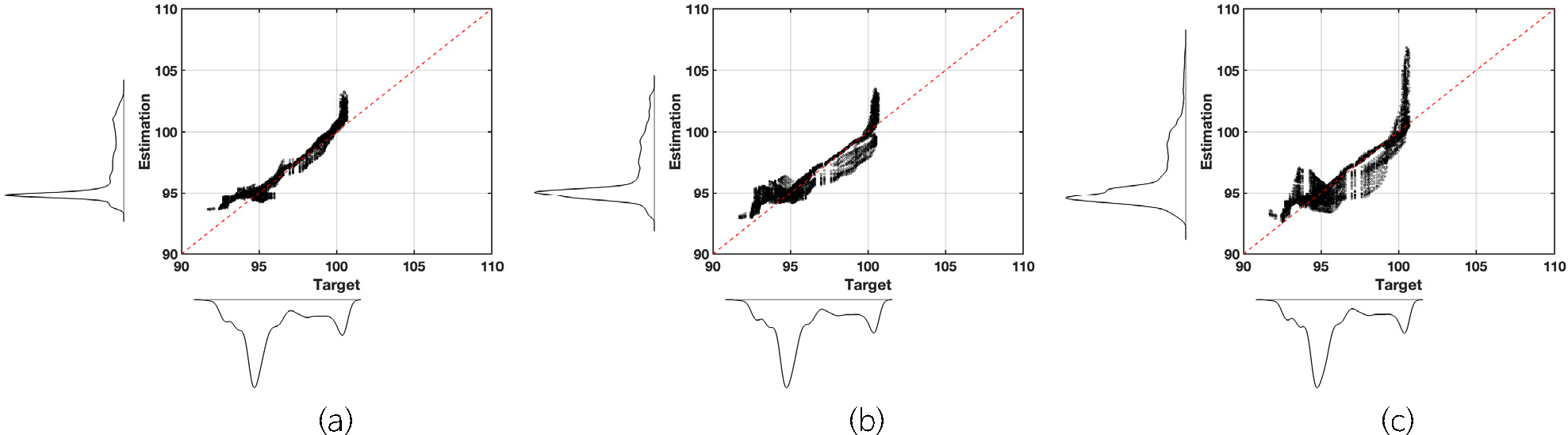
Table 2.
Quantitative performances of the three types of model for predicting groundwater level in test Case 2
| RMSE (m) | ρ | |
| Model 2-1 | 0.9939 | 0.9549 |
| Model 2-2 | 1.1376 | 0.8914 |
| Model 2-3 | 1.5310 | 0.8446 |
최종 예측 모델을 통한 중제주 수역 성능 검증 결과
본 연구에서 제시된 연구 과정을 기반으로 총 12개 지하수위 관정에 대하여 최종적으로 개발된 지하수위 예측 모델의 성능은 Table 3에 정리되었다. 표에서 보는 바와 같이 JW연동을 제외한 대부분 관정에서 실제 지하수위와 예측된 지하수위 간 0.5 m 이하의 작은 RMSE 값을 확인하였으며, ρ의 경우, 대부분 관정의 결과가 실제 지하수위와 대략 0.8 이상의 높은 상관성을 보임에 따라 개발된 예측 모델의 성능이 상당히 우수함을 확인할 수 있다. 이러한 결과는 관정별 개발된 모델이 미래 지하수위를 예측하는 데 적합함을 의미한다.
Table 3.
Quantitative performances of the developed models for each groundwater level monitoring station
결 론
본 연구에서는 stacked-LSTM을 이용하여 제주 중제주 수역 내 위치하는 총 12개 지하수위 관정에 대하여 미래 30일 동안의 지하수위를 예측할 수 있는 모델을 개발하였다. JI오등1, JI오등2, JI오등4, JI오등5, JD용담1, JM도남2, JM이도2, JP오라, JW공항, JW연동, JW일도, 및 금산수원지에 대하여 개별적인 예측 모델이 개발되었으며, 2001년에서 2022년 동안 관측된 일 단위 강수량, 지하수 이용량, 및 지하수위 자료가 예측 모델개발에 활용되었다. 강수량 자료는 총 3개의 관측소에서 확보되었으며, 지하수 이용량은 총 259개의 관측소에서 확보된 자료가 모델개발에 이용되었다. 입력자료의 종류 및 과거 활용자료의 순차 길이에 따라 다양한 모델을 구축하고 성능을 비교함으로써 예측 모델개발에 있어 고려해야 할 사항에 대한 검토를 수행하고, 최종 예측 모델을 제시함으로써 딥러닝 기반의 지하수위 예측 모델 구축을 위한 적합한 연구 과정을 제시하였다.
예측 모델개발 결과, 강수량, 지하수 이용량 및 과거 지하수위를 모두 입력자료로 활용하는 모델의 예측성능이 가장 뛰어난 것으로 확인되었으며, 제주도의 강수와 지하수위 변동 간의 패턴을 고려하였을 때, 입력으로 활용되는 과거 자료의 순차가 길수록 예측의 성능이 향상됨을 확인하였다. 이뿐만 아니라, 지하수 이용량 자료의 경우, 모든 이용량 자료를 활용하는 것보다 예측하고자 하는 지점의 지하수위에 민감한 영향을 주는 관정을 선별하여 입력으로 이용하는 것이 예측 모델의 성능 개선에 긍정적 영향을 주는 것을 확인하였다.
본 연구에서 개발된 지하수위 예측 모델은 현재의 강수량 및 지하수 이용량을 기반으로 미래의 지하수위를 예측할 수 있다. 이처럼 미래의 지하수량에 대한 건전성 정보를 제공함에 따라 적정 지하수량 유지를 위한 다양한 관리방안 마련에 도움이 될 것으로 판단된다. 다만 본 연구에서는 민감도분석을 통해 각 지하수위 관측정마다 연관성이 높은 지하수 이용 위치를 선별하였으나, 해당 결과에 대한 실제 현장 검증은 이루어지지 않았다. 이는 중제주 수역의 3차원 지하 매질 분포도가 확보될 경우, 검증이 이루어질 것으로 판단되며, 이에 관한 추가 연구가 지속해서 수행될 필요가 있다. 이러한 과정을 통해 개발된 예측 모델의 성능과 정확도를 검증함으로써 더욱 신뢰 높은 예측 결과를 제공할 수 있을 것으로 보인다. 이뿐만 아니라, 본 연구에서는 30일 미래를 예측하는 모델을 개발하였으나 보다 장기 미래를 예측할 수 있는 모델이 개발될 필요가 있어 보인다. 이러한 개발된 모델은 다양한 강수 시나리오 및 지하수 이용 시나리오에 대한 지하수량 평가를 가능하게 하여 기상학적 가뭄 및 인위적 가뭄에 대한 대수층 수량 건전성 평가 및 가뭄 대비에 또한 활용될 수 있을 것으로 판단된다.